
Python 面向对象(初级篇)
Python 面向对象(初级篇)
概述
- 面向过程:根据业务逻辑从上到下写垒代码
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强…”
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,即:将之前实现的代码块复制到现需功能处。
| 123456789101112131415161718 | while True: if cpu利用率 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 硬盘使用空间 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 内存占用 > 80%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 |
随着时间的推移,开始使用了函数式编程,增强代码的重用性和可读性,就变成了这样
| 12345678910111213141516 | def 发送邮件(内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件(\’CPU报警\’) if 硬盘使用空间 > 90%: 发送邮件(\’硬盘报警\’) if 内存占用 > 80%: 发送邮件(\’内存报警\’) |
今天我们来学习一种新的编程方式:面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)
创建类和对象
面向对象编程是一种编程方式,此编程方式的落地需要使用 “类” 和 “对象” 来实现,所以,面向对象编程其实就是对 “类” 和 “对象” 的使用。
类就是一个模板,模板里可以包含多个函数,函数里实现一些功能
对象则是根据模板创建的实例,通过实例对象可以执行类中的函数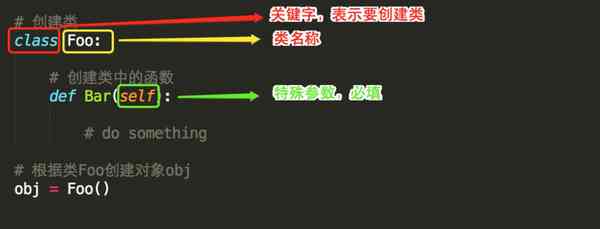
- class是关键字,表示类
- 创建对象,类名称后加括号即可
ps:类中的函数第一个参数必须是self(详细见:类的三大特性之封装)
类中定义的函数叫做 “方法”
| 12345678910111213 | # 创建类class Foo: def Bar(self): print \’Bar\’ def Hello(self, name): print \’i am %s\’ %name # 根据类Foo创建对象objobj = Foo()obj.Bar() #执行Bar方法obj.Hello(\’wupeiqi\’) #执行Hello方法 |
诶,你在这里是不是有疑问了?使用函数式编程和面向对象编程方式来执行一个“方法”时函数要比面向对象简便
- 面向对象:【创建对象】【通过对象执行方法】
- 函数编程:【执行函数】
观察上述对比答案则是肯定的,然后并非绝对,场景的不同适合其的编程方式也不同。
总结:函数式的应用场景 –> 各个函数之间是独立且无共用的数据
面向对象三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容
第一步:将内容封装到某处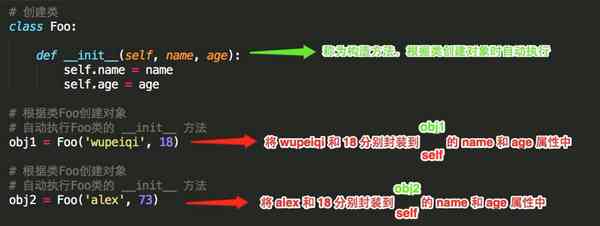
self 是一个形式参数
当执行 obj1 = Foo(‘wupeiqi’, 18 ) 时,self 等于 obj1
当执行 obj2 = Foo(‘alex’, 78 ) 时,self 等于 obj2
所以,内容其实被封装到了对象 obj1 和 obj2 中,每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。
第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
- 通过对象直接调用
- 通过self间接调用
1、通过对象直接调用被封装的内容
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名
| 12345678910111213 | class Foo: def __init__(self, name, age): self.name = name self.age = age obj1 = Foo(\’wupeiqi\’, 18)print obj1.name # 直接调用obj1对象的name属性print obj1.age # 直接调用obj1对象的age属性 obj2 = Foo(\’alex\’, 73)print obj2.name # 直接调用obj2对象的name属性print obj2.age # 直接调用obj2对象的age属性 |
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容
发“更快更好更强…”
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,即:将之前实现的代码块复制到现需功能处。
| 123456789101112131415161718 | while True: if cpu利用率 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 硬盘使用空间 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 内存占用 > 80%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 |
随着时间的推移,开始使用了函数式编程,增强代码的重用性和可读性,就变成了这样
| 12345678910111213141516 | def 发送邮件(内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件(\’CPU报警\’) if 硬盘使用空间 > 90%: 发送邮件(\’硬盘报警\’) if 内存占用 > 80%: 发送邮件(\’内存报警\’) |
今天我们来学习一种新的编程方式:面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)
创建类和对象
面向对象编程是一种编程方式,此编程方式的落地需要使用 “类” 和 “对象” 来实现,所以,面向对象编程其实就是对 “类” 和 “对象” 的使用。
类就是一个模板,模板里可以包含多个函数,函数里实现一些功能
对象则是根据模板创建的实例,通过实例对象可以执行类中的函数
- class是关键字,表示类
- 创建对象,类名称后加括号即可
ps:类中的函数第一个参数必须是self(详细见:类的三大特性之封装)
类中定义的函数叫做 “方法”
| 12345678910111213 | # 创建类class Foo: def Bar(self): print \’Bar\’ def Hello(self, name): print \’i am %s\’ %name # 根据类Foo创建对象objobj = Foo()obj.Bar() #执行Bar方法obj.Hello(\’wupeiqi\’) #执行Hello方法 |
诶,你在这里是不是有疑问了?使用函数式编程和面向对象编程方式来执行一个“方法”时函数要比面向对象简便
- 面向对象:【创建对象】【通过对象执行方法】
- 函数编程:【执行函数】
观察上述对比答案则是肯定的,然后并非绝对,场景的不同适合其的编程方式也不同。
总结:函数式的应用场景 –> 各个函数之间是独立且无共用的数据
面向对象三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容
第一步:将内容封装到某处
self 是一个形式参数
当执行 obj1 = Foo(‘wupeiqi’, 18 ) 时,self 等于 obj1
当执行 obj2 = Foo(‘alex’, 78 ) 时,self 等于 obj2
所以,内容其实被封装到了对象 obj1 和 obj2 中,每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。
第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
- 通过对象直接调用
- 通过self间接调用
1、通过对象直接调用被封装的内容
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名
| 12345678910111213 | class Foo: def __init__(self, name, age): self.name = name self.age = age obj1 = Foo(\’wupeiqi\’, 18)print obj1.name # 直接调用obj1对象的name属性print obj1.age # 直接调用obj1对象的age属性 obj2 = Foo(\’alex\’, 73)print obj2.name # 直接调用obj2对象的name属性print obj2.age # 直接调用obj2对象的age属性 |
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容