
爬取简书全站文章并生成 API(三)

简书
前两节介绍了从分析网页源码到爬取文章并将其保存在 MySQL 中的过程,如有不明白的,请务必看完前几节的介绍:
-
爬取简书全站文章并生成 API(一)
-
爬取简书全站文章并生成 API(二)
-
爬取简书全站文章并生成 API(四)
-
爬取简书全站文章并生成 API(五)
-
简书 API 测试地址 : http://222.24.63.118:8080/
-
github 项目地址:https://github.com/strugglingyouth/jianshu/
本节将介绍 API 的生成
Django 有自己的 Django REST framework 框架可以直接生成 API,在 Django 中生成 API 从复杂到简单有以下几种方式:
-
使用 Serializer 编写 API:使用 Serializer 类来编写 API 视图,这里我们不使用任何 REST framewrok 的其他特性,仅使用 Django 的常规方法编写视图。
-
使用基于函数视图的
@api_view重构代码:类视图中的装饰器提供了少许功能,比如确保在视图中接收Request实例,添加context到Resonse对象来决定返回类型。 -
使用类视图重写 API :更清晰的分离了 HTTP 的请求方法,将
method封装成了函数,不再需要使用if进行判断。 -
使用 Mixins 重构代码:
mixin类则提供了list()和ctreae()等行为,会显式绑定 GET 方法和 POST 方法对应的功能。 -
使用类的通用视图重构代码:让代码更简洁。
-
使用 ViewSets 和 Routers 重构代码:REST framework 提供了一种叫做 ViewSets 的抽象行为,它可以使开发人员聚焦于 API 的状态和实现,通过使用 Router 类来自动生成 URL 配置信息。
我使用的是 ViewSets 和 Routers 的方法,当然,这也是最常用的。以下是生成 API 的几个步骤:
-
编写 models:存储数据使用的字段
-
编写需要进行序列化的字段:将字段序列化为 JSON 的形式输出
-
编写 views:对数据进行的各种存取操作
-
编写 URL:访问 API 所使用的 URL
models 在上一节中已经写好,此处不再赘述。
编写需要进行序列化的字段
在 jianshu 目录下创建 serializers.py 文件,对应的目录结构如下所示:
目录树
创建 serializers 和创建 Django 表单类似,Django 提供了 Form 类和 ModelForm 类,同样的,REST framework 提供了 Serializer 类和 ModelSerializer。
#!/usr/bin/env python
# coding:utf-8
from models import ArticleList, ArticleDetail, HotArticle, SearchArticle
from rest_framework import serializers
class ArticleListSerializer(serializers.ModelSerializer):
\"\"\"
新上榜文章列表
\"\"\"
class Meta:
model = ArticleList
fields = (\'article_id\', \'article_title\', \'article_url\', \'article_user\', \'article_user_url\')
class ArticleDetailSerializer(serializers.ModelSerializer):
\"\"\"
新上榜文章详细信息
\"\"\"
class Meta:
model = ArticleDetail
fields = (\'image\', \'title\', \'body\', \'time\', \'views_count\', \'public_comments_count\', \'likes_count\', \'total_rewards_count\', \'article_abstract\')
class HotArticleSerializer(serializers.ModelSerializer):
\"\"\"
热门文章详细信息
\"\"\"
class Meta:
model = HotArticle
fields = (\'article_id\', \'article_url\', \'article_user\', \'article_user_url\', \'article_image\', \'article_title\', \'article_body\', \'article_time\', \'article_views_count\', \'public_comments_count\', \'article_likes_count\', \'total_rewards_count\' )编写 views
在 views 中使用 rest_framework 提供的 ViewSet 类,它提供了 read 以及 update 等操作。ViewSet 仅在被调用的时候才会和对应的方法进行绑定,当它被实例化时通常是在使用 Route 类管理 URL 配置的时候。
#coding:utf-8
from rest_framework import viewsets
from jianshu.serializers import ArticleListSerializer, ArticleDetailSerializer, HotArticleSerializer, SearchArticleSerializer
from jianshu.models import ArticleList, ArticleDetail, HotArticle, SearchArticle
class ArticleListViewSet(viewsets.ReadOnlyModelViewSet):
\"\"\"
新上榜文章列表
\"\"\"
queryset = ArticleList.objects.all().order_by(\"-created\")[:18]
serializer_class = ArticleListSerializer
class ArticleDetailViewSet(viewsets.ReadOnlyModelViewSet):
\"\"\"
新上榜文章详细信息
\"\"\"
queryset = ArticleDetail.objects.all().order_by(\"-created\")[:18]
serializer_class = ArticleDetailSerializer
class HotArticleViewSet(viewsets.ReadOnlyModelViewSet):
\"\"\"
热门文章详细信息
\"\"\"
queryset = HotArticle.objects.all().order_by(\"-created\")[:18]
serializer_class = HotArticleSerializerReadOnlyModelViewSet 自动提供了“只读”方法,然后按时间排序取出数据库中相应数量的文章。
编写 URL
使用 Router 类可以自动生成 URL,我们需要做的仅仅是正确的注册 View 到 Router 中:
from rest_framework.routers import DefaultRouter
from jianshu import views
router = DefaultRouter()
router.register(r\'article_news_list\', views.ArticleListViewSet)
router.register(r\'article_news_detail\', views.ArticleDetailViewSet)
router.register(r\'hot_article\', views.HotArticleViewSet)
urlpatterns = [
url(r\'^admin/\', admin.site.urls),
url(r\'^\', include(router.urls)),
]测试
启动服务:
# python manage.py runserver 222.24.63.118:8080在浏览器中访问:
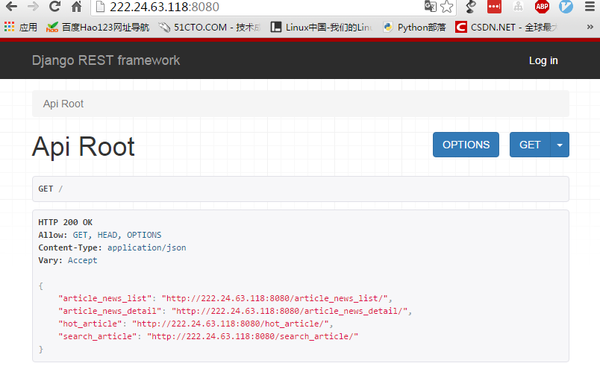
简书 API
下一篇:爬虫DAY-1