
爬取简书全站文章并生成 API(二)
admin
2023-07-30 21:45:36
0次

简书
第一节已经介绍了简书网站的结构,爬取文章前对网页源码进行必要的分析,以及整个项目的步骤,这一节开始介绍如何爬取简书分类目录下的文章,如有不明白的,请务必看完前一节的介绍:
-
爬取简书全站文章并生成 API(一)
-
爬取简书全站文章并生成 API(三)
-
爬取简书全站文章并生成 API(四)
-
爬取简书全站文章并生成 API(五)
-
简书 API 测试地址 : http://222.24.63.118:8080/
-
github 项目地址:https://github.com/strugglingyouth/jianshu/
爬取“新上榜”目录下的文章
说明: 所有代码都在 python2.7 环境下运行。
首先创建一个 Django 项目:
# django-admin startproject jianshu_api
# cd jianshu_api
# django-admin startapp jianshu在 jianshu_api/settings.py 下配置数据库:
DATABASES = {
\'default\': {
\'ENGINE\': \'django.db.backends.mysql\',
\'NAME\': \'jianshu\',
\'HOST\': \'127.0.0.1\',
\'USER\': \'root\',
\'PASSWORD\': \'tianfeiyu\',
\'PORT\': 3306
}
}开始写 models:
此 API 的设计是模仿知乎日报 API 的形式,models 分两层,第一层是概要信息,第二层是详细内容,以概要信息作为外键。
class ArticleList(models.Model):
\"\"\"
文章概要信息
\"\"\"
article_id = models.CharField(\'ID\', primary_key=True, max_length=100)
article_title = models.CharField(\'文章标题\', max_length=100)
article_url = models.URLField(\'文章URL\')
article_user = models.CharField(\'作者\', max_length=100)
article_user_url = models.URLField(\'作者URL\')
created = models.DateTimeField(auto_now_add=True)
class Meta:
ordering = [\'-created\', ]
def __unicode__(self):
return self.article_title
def __str__(self):
return self.article_title
class ArticleDetail(models.Model):
\"\"\"
文章详细信息
\"\"\"
image = models.URLField(\'图片URL\' )
title = models.CharField(\'文章标题\', max_length=100)
body = models.TextField(\'文章内容\', null=True)
time = models.CharField(\'发表时间\' , max_length=100, null=True)
views_count = models.CharField(\'阅读数\', max_length=100)
public_comments_count = models.CharField(\'评论数\', max_length=100)
likes_count = models.CharField(\'喜欢\', max_length=100)
total_rewards_count = models.CharField(\'打赏\', max_length=100)
created = models.DateTimeField(\'创建时间\', auto_now_add=True)
article_abstract = models.ForeignKey(\'ArticleList\', verbose_name=\'文章摘要\')
class Meta:
ordering = [\'-created\', ]
def __unicode__(self):
return self.title
def __str__(self):
return self.title然后进入 MySQL 中,设置使用的编码:
root@127.0.0.1 : (none) 09:41:33> set character_set_client=utf8 ;
root@127.0.0.1 : (none) 09:41:33> set character_set_connection=utf8 ;
root@127.0.0.1 : (none) 09:41:33> set character_set_database=utf8 ;
root@127.0.0.1 : (none) 09:41:33> set character_set_results=utf8 ;
root@127.0.0.1 : (none) 09:41:33> set character_set_server=utf8 ;
root@127.0.0.1 : (none) 09:41:33> set character_set_system=utf8 ;最后验证下是否正确:
设定 mysql 字符集
开始创建数据库:
# python manage.py makemigrations
# python manage.py migrate爬取“新上榜”的文章:
初始化代码:
if __name__ == \'__main__\':
# 从 jianshu_api/settings.py 文件中导入数据库的信息
host = DATABASES[\'default\'][\'HOST\']
user = DATABASES[\'default\'][\'USER\']
passwd = DATABASES[\'default\'][\'PASSWORD\']
db = DATABASES[\'default\'][\'NAME\']
port = DATABASES[\'default\'][\'PORT\']
# 保存文章所用到的表
article_list_table = \'jianshu_articlelist\'
article_detail_table = \'jianshu_articledetail\'
# 使用 colorama 模块进行颜色控制,通过使用 autoreset 参数可以让变色效果只对当前输出起作用,输出完成后颜色恢复默认设置
init(autoreset=True)
domain_name = \'http://www.jianshu.com\'
# “新上榜”目录的 URL
base_url = \'http://www.jianshu.com/recommendations/notes\'
# 初始化一个 mysql 实例
mysql = Mysql(host, user, passwd, db, port)
# 解析 dom,获取文章的详细信息
get_details(mysql, base_url, domain_name, article_list_table, article_detail_table)爬取文章详细信息代码:
def get_details(mysql, base_url, domain_name, article_list_table, article_detail_table):
\"\"\"
爬取文章并获取详细信息
\"\"\"
# OrderedDict() 是一个有序的字典,将文章的信息保存在 dict 中
article_list = OrderedDict()
article_detail = OrderedDict()
html = requests.get(base_url).content
# html 是网页的源码,soup 是获得一个文档的对象
soup = BeautifulSoup(html, \'html.parser\', from_encoding=\'utf-8\')
tags = soup.find_all(\'li\', class_=\"have-img\")
print Fore.YELLOW + \"---------------all-------------------:\",len(tags)
ct = 1
# 获取文章的信息
for tag in tags:
image = tag.img[\'src\'].split(\'?\')[0]
article_user = tag.p.a.get_text()
# 将 URL 补全
article_user_url = tag.p.a[\'href\']
if article_user_url.startswith(\'/users/\'):
article_user_url = domain_name + article_user_url
created = tag.p.span[\'data-shared-at\']
article_title = tag.h4.get_text(strip=True)
article_title = article_title.replace(\'\"\', \'\\\\\"\')
article_url = tag.h4.a[\'href\']
article_id = article_url.split(\'/\')[2]
if article_url.startswith(\'/p/\'):
article_url = domain_name + article_url
tag_a = tag.div.div.find_all(\'a\')
views = tag_a[0].get_text(strip=True)
# 提取其中的数字
views = filter(str.isdigit, str(views))
comments = tag_a[1].get_text(strip=True)
comments = filter(str.isdigit, str(comments))
tag_span = tag.div.div.find_all(\'span\')
likes = tag_span[0].get_text(strip=True)
likes = filter(str.isdigit, str(likes))
# 阅读,评论,喜欢一定存在,打赏不一定有
try:
tip = tag_span[1].get_text()
tip = filter(str.isdigit, str(tip))
except Exception as e:
tip = 0获取文章的内容:
def get_body(article_url):
\"\"\"
获取文章内容
\"\"\"
# 解析文章对应的 URL
html = requests.get(article_url).content
soup = BeautifulSoup(html, \'html.parser\', from_encoding=\'utf-8\')
tags = soup(\'div\', class_=\"show-content\")
body = str(tags[0])
# 将 body 中 \" 转换为 \\\", \' 转换为 \\\'
body = body.replace(\'\"\',\'\\\\\"\')
body = body.replace(\"\'\",\"\\\\\'\")
return body将数据保存在 mysql 中:
def insert_data(self, table, my_dict):
try:
# 从 dict 中分别取出 key,value
cols = \',\'.join(my_dict.keys())
values = \'\",\"\'.join(my_dict.values())
values = \'\"\' + values + \'\"\'
try:
sql = \"insert into %s (%s) values(%s)\" %(table, cols, values)
result = self.cur.execute(sql)
self.db.commit()
if result:
return 1
else:
return 0
except MySQLdb.Error as e:
self.db.rollback()
if \"key \'PRIMARY\'\" in e.args[1]:
print Fore.RED + self.get_current_time(), \"数据已存在,未插入数据\"
else:
print Fore.RED + self.get_current_time(), \"插入数据失败,原因 %d: %s\" % (e.args[0], e.args[1])
except MySQLdb.Error as e:
print Fore.RED + self.get_current_time(), \"数据库错误,原因%d: %s\" % (e.args[0], e.args[1])代码运行结果:
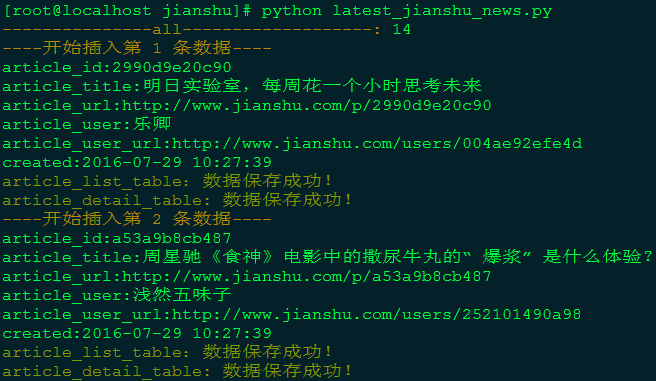
运行结果
上一节已经提到过,“热门”目录和“新上榜”目录下代码的结构相同,所以以上代码稍作修改完全可以爬取“热门”下的文章,但我将“热门”下爬取到的文章放在了一张表里,大家可以自行尝试。
完整代码请查看项目中的 popular_articles_jianshu.py 文件!
下一节将介绍 API 的生成。
上一篇:python模块导入的问题
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...