
collections 模块(1)
摘要
collections 模块用得很多,因为它提供了一些非常高效的容器数据类型。掌握这些数据类型能显著提高编码的效率。这篇文章会对 Python 2 和 Python 3 共有的 5 种数据类型加以总结,至于 Python3 中特有的另外 4 种数据类型会出现在后续的文章中.
简介
collections 提供的五种数据类型分别是:
| 数据类型 | 初始化参数 |
|---|---|
| namedtuple() | (typename, field_names[, verbose=False][, rename=False]) |
| deque | ([iterable[, maxlen]]) |
| Counter | ([iterable-or-mapping]) |
| OrderedDict | [items] |
| defaultdict | ([default_factory[, …]]) |
注意到上表中的 namedtuple() 带有括号,说明其是一个函数,而剩余的四种数据类型都是类。函数可以返回一个返回值,而类可以实例化一个对象。
namedtuple()
-
namedtuple() 返回一个类
namedtuple返回的是一个类(class), 类可以用来实例化一个对象。例如:from collections import * Person = namedtuple(\'Person\', [\'age\', \'sex\'])上面的代码其实创建了一个类,这个类的类名叫做 \’Person\’ , 这个类有两个属性,分别是 \’age\’ 和 \’sex\’ . 我们可以用这个类创建实例。例如
person = Person(10, \'male\')上面这段代码创建了一个 age=10, sex=male 的 Person 的对象 person.
-
nametuple() 创建named tuple
namedutple() 有四个参数,第一个参数 typename 是返回的类的名称,类的名称必须要是合法的变量名。第二个参数是属性名称,在上面我们已经看到了可以用list列出所有的属性名。事实上,我们还可以使用一个字符串来列举所哟逇属性名,这时需要使用空格或者逗号作为属性名之间的分隔符。例如:Person = namedtuple(\'Person\', \'age sex\') Person = namedtuple(\'Person\', \'age,sex\')第三个参数保证其默认值即可。
第四个参数默认为False,如果为True,在设置属性名称的时候可以设置成重复,但会被自动重命名为下划线与数字的组合. 例如:Person = namedtuple(\'Person\', \'age,age,height,age\') p = Person(age=10,_1=\'male\',height=1.80\',_3=\'32\') -
namedtuple 和 tuple的异同
顾名思义,namedtuple 是带有名字的tuple. 我们创建了一个tuple之后,要访问这个tuple的元素只能利用这个tuple的索引。比如:t = (1,2,3) x = t[1] y = t[0] z = t[2]但是如果创建的是一个namedtuple, 既可以使用索引访问namedtuple的元素,也可以用属性名访问。例如:
Person = namedtuple(\'Person\',\'age, sex\') p = Person(15, \'male\') age0 = p.age age1 = p[0] sex0 = p.sex sex1 = p[1] -
namedtuple 类中的几种方法:
- 类方法
- _make(iterable):把iterable变成一个named tuple 并且返回。
- 成员方法
- _replace(kwargs):用新的值去替代named tuple的属性值并且返回新的named tuple(原来的named tuple 没有改变)。
- _asdict() 成员方法: 返回一个OrderDict对象,OrderDict 的 key 是 named tuple 的属性名, value是 named tuple 的属性值。
- 类方法
-
from collections import namedtuple Person = namedtuple(\'Person\', \'height weight age sex\') p = Person(177, 129, 22, \'male\') t = [180, 130, 25, \'male\'] nt = Person._make(t) pr = p._replace(age = 21) pd = p._asdict() print(nt) print(pr) print(pd) >>> Person(height=180, weight=130, age=25, sex=\'male\') Person(height=177, weight=129, age=21, sex=\'male\') OrderedDict([(\'height\',177), (\'weight\',129), (\'age\',22), (\'sex\', \'male\')]) - 利用已有的 named tuple 创建新的named tuple。举个例子:
Point = namedtuple(\'Point\',\'x y\') ## 坐标为x,y的一个点 Color = namedtuple(\'Color\', \'r g b\')现在要创建一个又坐标和颜色组成的像素点, 可以这样:
Pixel = namedtuple(\'Pixel\', Point._fields + Color._fields)当然也能直接创建:
Pixel = namedtuple(\'Pixel\', \'x y r g b\')这两种方式没有什么本质区别,但是第一种方法更加的结构化。
deque
deque 就是一个双端链表, 如下图:
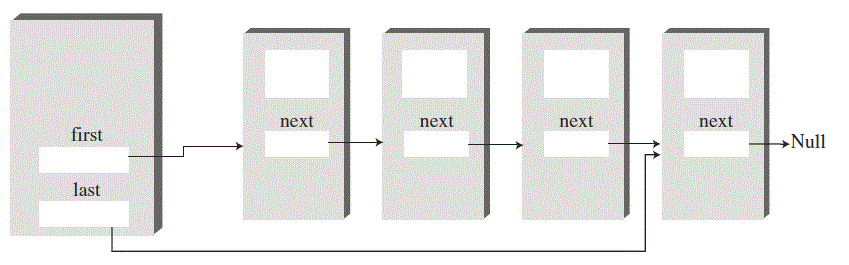
deque.gif
- 创建一个双端链表:
d0 = deque() # 空双端链表 d1 = deque(\'abcde\') # 有5个元素的双端链表 d2 = deque([1,1,2,3,5,8,11], 20) # 有7个元素的双端链表,并且最大长度不能超过20 - 操作deque的方法
- append(x): 在尾部添加一个元素
- appendleft(x): 在首部添加一个元素
- clear(): 清空deque
- count(x):统计在deque中x出现的次数并返回
- extend(iterable):在尾部添加一个iterable
- extendleft(iterable):在首部添加一个iterable
- pop():从尾部移除一个元素并且返回这个元素
- popleft():从首部移除一个元素并且返回这个元素
- remove(value): 移除整个deque中从左到右第一个出现的元素
- reverse():在原位翻转整个deque
- rotate(n):如果n为正数,整个deque循环右移n位。如果n为负数,循环左移n位
注意到成员方法reverse()是在原位置做翻转,返回的是None. 然而函数reversed(iterable) 会返回一个新的iterator, 不会影响其参数iterable. 例如
d = deque(\'abcd\')
d.reverse()上面的d此时已经变成了deque(\’dcba\’), 然而下面的代码给出了另外一种情况
d = deque(\'abcd\')
rd = reversed(d)
lrd = list(rd)d 依然保持不变,rd 是一个iterator, lrd 则是 [\’d\’, \’c\’,\’ b\’, \’a\’]
- 用deque 实现栈和队列
- 实现栈: 栈是一种先入后出的数据结构,deque的append(x)方法可以用来实现入的过程,而pop()则可以用来实现出的过程。因此栈的push(x) 和 pop() 方法可以用 deque 的 append(x) 和 pop() 轻松实现。
- 实现队列: 队列是一种先入先出的数据结构,deque 的 append(x)方法可以用来实现入的过程,而 popleft() 则可以用来实现出的过程。
s = deque(\'abcd\')
s.append(\'e\') # 入栈
s.append(\'f\') # 入栈
s.pop() # 出栈
q = deque(\'xyz\')
q.append(\'a\') # 入队
q.append(\'b\') # 入队
q.popleft() # 出队Counter
Counter 是一个计数器,当我们有计数需求的时候,使用它十分方便。例如我们需要统计一个字符串每个字符出现的次数,直接用Counter就可以帮我们搞定了。Counter 是 dict 的一个子类,因此dict 的方法可以直接用到 Counter 上来。
- 创建Counter
c0 = Counter()
c1 = Counter(\'abaabcd\')
print(c0)
print(c1)
>>>
Counter()
Counter({\'a\': 5, \'d\': 3, \'f\': 3, \'b\': 2, \'e\': 1, \'c\': 1})因为Counter本身是一个dict, 所以我们可以随心所欲往Counter里面添加键值对.
c1[\'k\'] = 5当然我们在初始化的时候也可以用dict去初始化一个Counter
cnt = Counter({\'apple\':5, \'peach\':10})
print(cnt)
>>>
Counter({\'apple\': 5, \'peach\': 10})- 操作Counter的成员方法
- elements() :
- most_common([n]):
- subtract([iterable-or-mapping]):
- update([iterable-or-mapping]):
## elements() 返回的是一个iterator. 每个元素是Counter里面的key,每个元素出现的次数是key对应的值
cnt1 = Counter(\'abcdeaaabcde\')
list(cnt1.elements())
>>>
[\'b\', \'b\', \'e\', \'e\', \'c\', \'c\', \'d\', \'d\', \'a\', \'a\', \'a\', \'a\']## most_common([n]) 返回一个list, 这个list的元素是一个tuple。这个tuple包含两个值,第一个值是key, 第二个值是key出现的次数。
cnt1.most_common()
cnt1.most_common(3)
>>>
[(\'a\', 4), (\'b\', 2), (\'e\', 2), (\'c\', 2), (\'d\', 2)]
[(\'a\', 4), (\'b\', 2), (\'e\', 2)]## subtract(iterable-or-mapping) 会先统计iterable or mapping, 然后已有的Counter的统计值会减去相应的值得到新的值。
s = \'fashifdap\'
cnt2 = Counter(s)
print(cnt2)
cnt1.subtract(s)
print(cnt1)
>>>
Counter({\'a\': 2, \'d\': 1, \'f\': 2, \'h\': 1, \'i\': 1, \'p\': 1, \'s\': 1})
Counter({\'a\': 2, \'b\': 2, \'c\': 2, \'d\': 1, \'e\': 2, \'f\': -2, \'h\': -1, \'i\': -1, \'p\': -1, \'s\': -1})## update(iterable or mapping) 会在已有的Counter的基础上加上iterable 或者 mapping的统计值
cnt1.update(\'xxxxxxx\')
cnt1.update({\'s\': -5}
print(cnt1)
>>>
Counter({\'a\': 2, \'b\': 2, \'c\': 2, \'d\': 1, \'e\': 2, \'f\': -2, \'h\': -1, \'i\': -1, \'p\': -1, \'s\': -6, \'x\': 7})- 操作Counter的其他方式
- +: 两个Counter相加,返回新的Counter。如果是有元素的出现次数在新的Counter中为负数,则在返回的Counter中抛弃该元素。
- -:两个Counter相减,返回新的Counter。如果是有元素的出现次数在新的Counter中为负数,则在返回的Counter中抛弃该元素。
- &:两个Counter相与,返回新的Counter。新的Counter的key必须同时出现过并且为出现次数必须为正。选择一个最小的正数,作为当前key的value
- |:两个Counter相或,返回新的Counter。新的Counter的key必须至少在两个Counter中的一个出现过并且为正。选择一个最大的正数,作为当前key的value
from collections import Counter
cnt1 = Counter(\'aaaabcjjjjjjjj\')
cnt2 = Counter({\'a\': -2, \'b\':3, \'k\': 9, \'j\': -7})
print(\"cnt1: \", cnt1)
print(\"cnt2: \", cnt2)
print(\"cnt1 + cnt2: \", cnt1 + cnt2)
print(\"cnt1 - cnt2: \", cnt1 - cnt2)
print(\"cnt1 & cnt2: \", cnt1 & cnt2)
print(\"cnt1 | cnt2: \", cnt1 | cnt2)
>>>
cnt1: Counter({\'j\': 8, \'a\': 4, \'c\': 1, \'b\': 1})
cnt2: Counter({\'k\': 9, \'b\': 3, \'a\': -2, \'j\': -7})
cnt1 + cnt2: Counter({\'k\': 9, \'b\': 4, \'a\': 2, \'j\': 1, \'c\': 1})
cnt1 - cnt2: Counter({\'j\': 15, \'a\': 6, \'c\': 1})
cnt1 & cnt2: Counter({\'b\': 1})
cnt1 | cnt2: Counter({\'k\': 9, \'j\': 8, \'a\': 4, \'b\': 3, \'c\': 1})OrderedDict
- OrderedDict 和 dict 之间异同
OrderedDict 和 dict 的不同之处在于:dict 里面的元素是无序的,而OrderedDict里面的元素是有序的。它的有序之处体现在:先插入的元素排在前面,后插入的元素排在后面。例如:
from collections import *
od = OrderedDict()
d = {}
fruits = [\'apple\', \'peach\', \'pear\', \'dragon\', \'blueberry\', \'orange\']
for f in fruits:
od[f] = 10
d[f] = 10
print(od)
print(d)
>>>
OrderedDict([(\'apple\', 10), (\'peach\', 10), (\'pear\', 10), (\'dragon\', 10), (\'blueberry\', 10), (\'orange\', 10)])
{\'apple\': 10, \'peach\': 10, \'blueberry\': 10, \'pear\': 10, \'orange\': 10, \'dragon\': 10}我们看到od里面的元素按照我们的插入顺序排列,而d中的元素则无序排列
- popitem(last=True)
OrderedDict有一个成员方法 popitem. 如果last为True, 则从尾部pop出一个元素,这也是默认的。如果last为False, 则从首部pop出一个元素。例如:
t = od.popitem()
f = od.popitem(last=False)
print(t)
print(f)
>>>
(\'orange\', 10)
(\'apple\', 10)- 用 OrderedDict 实现LRU:
我们知道LRU要求我们最先访问容器中最后被插入的元素,且该元素在容器中不能重复。基于这个特点,我们可以用OrderedDict实现LRU如下:
class LRU(OrderedDict):
def __setitem__(self, key, value):
if key in self:
del self[key]
OrderedDict.__setitem__(self, key, value)
else:
OrderedDict.__setitem__(self, key, value)defaultdict
在使用dict的时候,如果没有某一键值对,那么去访问这个键是会报错的。比如说:
d = {\'apple\': 5, \'peach\': 10}如果去访问d[\’dragon\’]是会报错的,因为dragon不存在与d中。defaultdict就是为了解决这个问题诞生的。例如:
dd = defaultdict(int)
print(dd[\'dragon\'])
>>>
0上面的代码告诉我们如果某一个键值对在defaultdict中不存在,如果去访问会默认返回一个int。并且会把这个键值对加入到defaultdict中去。当然如我们把int改成其他任何类型也是可以的,比如说list, tuple 等等等等。例如:
dd = defaultdict(list)
dd[\'dragon\'] = 10
print(dd[\'apple\'])
print(dd)
>>>
[] ## 返回一个默认的list
defaultdict(, {\'dragon\': 10, \'apple\': []}) ## {\'apple\': []} 这个键值对被加入到了dd中去 如果defaultdict 不设置参数,那么和dict一样,访问不存在的键值对会报错。例如:
dd = defaultdict()
print(dd[\'apple\'])
>>>
KeyError: \'apple\' ## 因为\'apple\'是不存在的键值,并且没有指定默认返回值,故报错
上一篇:用Python爬取妹子图——基于BS4+多线程的处理
下一篇:Python 装饰器