
一个简单的人肉刷票机演示
admin
2023-07-30 20:45:31
0次
随着网络投票的兴起,刷票工具也应运而生。相关的技术分析也看了不少,正好碰上个机会,用python做了一个基于urllib的简单人肉刷票机。重点在思路分析和练手,所以下面把目标站点的信息都擦了,主要看个思路,不建议大家做坏事哟~
投票场景基本分析
首先浏览一下投票页面,试着投了一票。发现再打开投票链接的时候浏览器就提示“你已参加过投票活动”。不可能靠IP识别用户,基本就是靠cookie了,果然清空一下就能反复投票,也没有发现对其它用户特征的识别限制。不过投票之前要先点击“获取验证码”,获取一个验证码图片进行输入验证,获取过程应该就是JS触发一个GET请求,验证码也都是规整的字母数字,估计随便找个在线OCR能搞定(好吧这里是我天真了),反正先按照套路接下来就是分析投票的HTTP请求,试着用程序模拟了。
HTTP请求分析
各类文章对HTTP请求的分析也很多,就不详细说了,挂上Burpsuit直接看结果:
先看看访问投票页面的响应,有用的信息有几个:
- 头部Set-Cookie的内容
- 返回页面上验证码区域有一个\”InstanceId\”参数
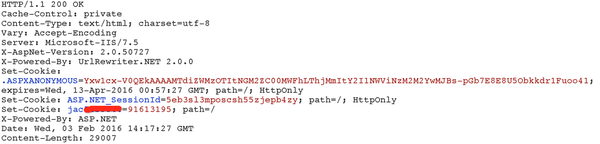
投票首页的返回头部
![]()
投票首页返回部分内容
再看拦截到的请求验证码的过程
- GET请求里有两个变化的参数 t和d,t就是投票页面返回的那个InstanceId,(和上面那张图里的参数不一样..因为不是一次过程的,我懒得找了=、=),d目测是个时间参数,事实证明删了也无妨..于是就被我去掉了。(后面提交投票的时候也有这个参数,那个时候就不能忽略了)
- 注意这个请求是带cookie的,经测试没有cookie的话,请求出来的永远都是同一张图片。后来分析应该是它在后台根据cookie里jac这个字段和t一起去随机匹配了一个图片,并在后台和jac关联了,提交之后根据这个进行验证。
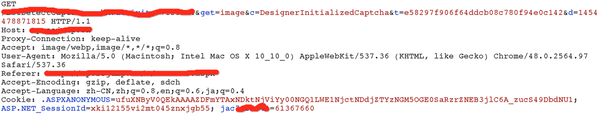
请求验证码图片的请求报文头
插曲
到这里,已经能通过模拟获得验证码了,本来打算用个在线OCR识别一下做成全自动,然而在做参数试验的时候,网站对提交应该是有防护预警的,识别到可疑行为之后先是暂停了一下,再开放之后验证码难度飙升,各种扭曲旋转中文字,反正它对单IP的访问频率也有限制,俺们也不是真的要做坏事,这里就搞成人肉模式了,获取验证码之后会弹出图片和程序输入提示,人肉识别输入完成提交。
提交的请求
先吐槽一下,这里的数据提交都还是用GET请求..基本没什么问题
- rn参数里前半段是固定的,后半段就是cookie里jac的数值
- t参数,就是当前时间,time.time()*1000
- validate_text和btuserinput是验证字符串,urlencoded
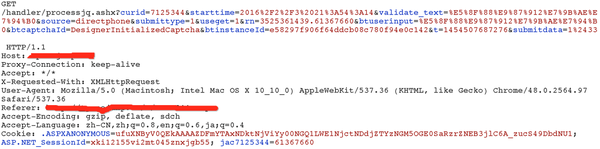
提交投票请求
一路提交完,刷一下页面就可以看到投票成功咯~
几个思考
- 后面代码里可以看到,这种模拟还是比较低级的,包括手动处理cookie信息。后来查到有一些库在模拟浏览器会话上做了高层封装,应该会更方便,以后可以进一步研究。
- 图片验证码? 随着识别技术不断发展,纯粹的图片验证码要么就是分分钟被程序做掉,要么就是分分钟把用户做掉(对啊对啊,我说的就是你,12xxx)。不知道未来的方向会是怎么样,现在开始出现越来越多基于行为的验证码输入(比如要你拖动滑块完成图片拼图),搜到很多似乎都是来自极验验证的,也许是今后的一个趋势。
- 网站防护与数据分析。当传统的验证手段越来越难以阻止用户进行非常规操作(我觉得今后业余用户能写几手代码抓几行包的能力会越来越强,何况还有这么多工具提供者),我们如果作为网站的运营维护人员,要怎么应对?答案也许在于对访问数据的充分挖掘和分析上。我自己的观念也在转变,做好网站安全,并不是上一套一套安全设备,一个个检查特征库更新全,补丁打完就够了。漏洞防不胜防,总有各种0day,依赖对已知攻击的特征检查和防护永远慢人一步。而如果能从更多的方面来分析访问请求、从数据统计上着手,也许我们距离最前沿的攻击就只差半步了。当然现实往往是残酷的,很多网站也许根本就倒在了第一步“数据收集”,要么信息不全要么记录漫无目的。其实这也许才是最重要的一步,该记录哪些数据?记在哪里?怎么记?能否有效快速访问?这一步做好了,后面的分析处理就可以天马行空了。像我这次这样简单的刷票应该分分钟就被干掉或者统计时就被排除掉了^^
最后附上代码,比较简单就没有写注释(好吧我承认还是因为我懒),和上面的过程是一样的~大家不要做坏事哟~
#coding=utf-8
from BeautifulSoup import *
import cStringIO
import urllib
import re
from PIL import Image
import time
import urllib2
url1 = \'http://www.example.com/\'
url2 = \'http://www.example.com/***?activity=***&get=image&c=DesignerInitializedCaptcha&t=\'
while True:
cookie = \'\'
iid = \'\'
page = urllib.urlopen(url1)
for header in page.info().headers:
if \'Set-Cookie\' in header:
cookie += re.findall(r\'Set-Cookie:( \\S*;)\',header)[0]
rnd = re.findall(r\'jac*****=(.*);\',cookie)[0]
soup = BeautifulSoup(page)
tags = soup(\'img\')
for tag in tags:
if tag.get(\'instanceid\', None):
iid = tag.get(\'instanceid\')
req = urllib2.Request((url2 + iid))
req.add_header(\'Host\',\' www.example.com\')
req.add_header(\'Proxy-Connection\',\'keep-alive\')
req.add_header(\'Accept\',\'image/webp,image/*,*/*;q=0.8\')
req.add_header(\'Referer\',\'http://www.example.com/\')
req.add_header(\'User-Agent\',\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.97 Safari/537.36\')
req.add_header(\'Accept-Encoding\',\'gzip, deflate, sdch\')
req.add_header(\'Accept-Language\',\'zh-CN,zh;q=0.8,en;q=0.6,ja;q=0.4\')
req.add_header(\'Cookie\', cookie)
cfile = cStringIO.StringIO(urllib2.urlopen(req).read())
img = Image.open(cfile)
img.show()
cpt = raw_input(\'验证码是多少:\')
data = {\'validate_text\':cpt, \'source\':\'directphone\', \'submittype\':\'1\', \'rn\':\'3525361439.\'+rnd, \'btuserinput\':cpt, \'btcaptchaId\':\'DesignerInitializedCaptcha\', \'btinstanceId\':iid, \'t\':str(int(time.time()*1000)), \'submitdata\':\'1$29|31|32|33\', \'useget\':1}
url3 = \'http://www.example.com/***?curid=7125344&starttime=2016%2F2%2F3%2019%3A32%3A15&\' + urllib.urlencode(data)
req = urllib2.Request(url3)
req.add_header(\'Host\',\' www.example.com\')
req.add_header(\'Proxy-Connection\',\'keep-alive\')
req.add_header(\'Accept\',\'*/*\')
req.add_header(\'X-Requested-With\',\'XMLHttpRequest\')
req.add_header(\'Referer\',\'http://www.example.com/\')
req.add_header(\'User-Agent\',\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.97 Safari/537.36\')
req.add_header(\'Accept-Encoding\',\'gzip, deflate, sdch\')
req.add_header(\'Accept-Language\',\'zh-CN,zh;q=0.8,en;q=0.6,ja;q=0.4\')
req.add_header(\'Cookie\', cookie)
result = urllib2.urlopen(req)
print result.read()
time.sleep(10)相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...