
Python抓取网页数据 生成 iOS plist 文件
admin
2023-07-30 20:44:00
0次
闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干
- 准备搭建环境
- 因为是MAC电脑,所以自动安装了Python 2.7的版本
- 添加一个 库 Beautiful Soup ,方法这里说两种
- 1.在终端输入 pip install BeautifulSoup
- 2.手动下载包后,终端切换到 解压的文件夹,输入 sudo python setup.py install 下载地址BeautifulSoup
- 添加一个 库 Beautiful Soup ,方法这里说两种
- 因为是MAC电脑,所以自动安装了Python 2.7的版本
-
开始写代码吧
- 先找一个想要抓取东西的网站,这里我就随便找一个吧 地址是:http://movie.douban.com/chart
- 好了在终端输入 vim 我知道这个东西,对于新手来说,就是一个挑战,这里我也建议使用轻量的Sublime
- 代码如下 (注意python是严格的缩进,以下代码要顶格写)
#-*- coding:utf-8 -*- import urllib2 import urllib html=urllib2.urlopen(\"http://movie.douban.com/chart\").read() print html
-
输出的结果就是一个HTML的网页,这里我就看到自己想要抓取的图片和图片名的文字片段

- 分析我们想要的,一个是图片的名称,一个是图片的链接地址,直接上Python代码
#-*- coding:utf-8 -*-
import urllib2
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding(\'utf8\')
# 函数
def printPlistCode():
#1.得到这个网页的 html 代码 #
html = urllib2.urlopen(\"http://movie.douban.com/chart\").read()
#2.转换 一种格式,方便查找
soup = BeautifulSoup(html)
#3. 得到 找到的所有 包含 a 属性是class = nbg 的代码块,数组
liResutl = soup.findAll(\'a\', attrs = {\"class\" : \"nbg\"})
#4.用于拼接每个字典的字符串
tmpDictM = \'\'
#5. 遍历这个代码块 数组
for li in liResutl:
#5.1 找到 img 标签的代码块 数组
imageEntityArray = li.findAll(\'img\')
#5.2 得到每个image 标签
for image in imageEntityArray:
#5.3 得到src 这个属性的 value 后面也一样 类似 key value
link = image.get(\'src\')
imageName = image.get(\'alt\')
#拼接 由于 py中 {} 是一种数据处理格式,类似占位符
tmpDict = \'\'\'@{0}@\\\"name\\\" : @\\\"{1}\\\", @\\\"imageUrl\\\" : @\\\"{2}\\\"{3},\'\'\'
tmpDict = tmpDict.format(\'{\',imageName,link,\'}\')
tmpDictM = tmpDictM + tmpDict
#6.去掉最后一个 ,
tmpDictM = tmpDictM[0:len(tmpDictM) - 1].decode(\'utf8\')
#7 拼接全部
restultStr = \'@[{0}];\'.format(tmpDictM)
print restultStr
if __name__ == \'__main__\':
printPlistCode()- 输出结果就是Objective-C的 数组
@[@{@\"name\" : @\"进击的巨人真人版:前篇\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2251690571.jpg\"},@{@\"name\" : @\"花与爱丽丝杀人事件\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2222398443.jpg\"},@{@\"name\" : @\"小黄人大眼萌\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2258235689.jpg\"},@{@\"name\" : @\"小森林 冬春篇\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2215147728.jpg\"},@{@\"name\" : @\"道士下山\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2251450614.jpg\"},@{@\"name\" : @\"深夜食堂 电影版\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2205014862.jpg\"},@{@\"name\" : @\"小男孩\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2230105606.jpg\"},@{@\"name\" : @\"头脑特工队\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2231021196.jpg\"},@{@\"name\" : @\"百元之恋\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2205471169.jpg\"},@{@\"name\" : @\"杀破狼2\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2246885606.jpg\"}];- 使用Xcode 写到Plist中去
#import
int main(int argc, const char * argv[]) {
NSArray *plistArray = @[@{@\"name\" : @\"进击的巨人真人版:前篇\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2251690571.jpg\"},@{@\"name\" : @\"花与爱丽丝杀人事件\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2222398443.jpg\"},@{@\"name\" : @\"小黄人大眼萌\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2258235689.jpg\"},@{@\"name\" : @\"小森林 冬春篇\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2215147728.jpg\"},@{@\"name\" : @\"道士下山\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2251450614.jpg\"},@{@\"name\" : @\"深夜食堂 电影版\", @\"imageUrl\" : @\"http://img3.douban.com/view/movie_poster_cover/ipst/public/p2205014862.jpg\"},@{@\"name\" : @\"小男孩\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2230105606.jpg\"},@{@\"name\" : @\"头脑特工队\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2231021196.jpg\"},@{@\"name\" : @\"百元之恋\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2205471169.jpg\"},@{@\"name\" : @\"杀破狼2\", @\"imageUrl\" : @\"http://img4.douban.com/view/movie_poster_cover/ipst/public/p2246885606.jpg\"}];
//路径可以自己选择
[plistArray writeToFile:@\"/Users/xxx/Desktop/test/movie.plist\" atomically:YES];
return 0;
} - 到这里,就可以看到plist 文件可以用于测试了
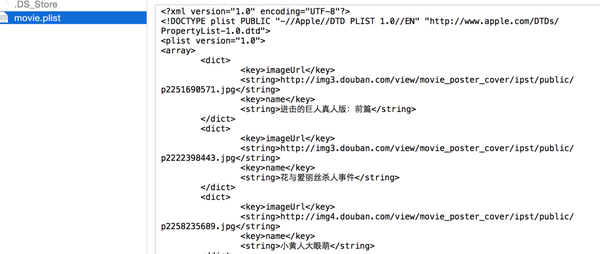
这里写图片描述 - 如果想要复制粘贴这里面的代码,那就选择Sublime编辑器
上一篇:Python mixin模式
下一篇:django: 微信网页授权
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...