
Apache Doris 常见适用场景浅析 MPP 架构的 OLAP 列式存储数据库
什么是 Apache Doris
Apache Doris 是一款 MPP 架构的 OLAP 列式存储数据库。
三个显示关键词及一个隐式关键词:MPP 架构、OLAP、列式存储以及隐藏的全面向量化。
那么除去这些看起来很高大上的修饰术语,得到的是:Apache Doris 是一款数据库。
但是这个数据库究竟有什么优势,它能做哪些场景的事,我们根据这些信息还是无法一目了然的了解。
本篇将给大家做一次梳理,让不了解\不清楚\不知道 Apache Doris 适用于哪些应用场景的同学,快速对其的应用覆盖范围有一个大致的了解,后续会有八篇《Apache Doris 适用场景—— XX 详解》这样的分篇来详细描述分类场景,此篇为浅析和纲要。
为什么选择 Apache Doris

以下文字可作为材料贴入选型理由:
运维成本低
部署简单,二进制包解压缩配置即可
扩缩容简单,无需人工干预 reblance
强大的自愈能力,定期自动进行 bad tablet 修复
使用成本低
高度兼容 MySQL 协议,支持 MySQL 链接的地方就能用 Doris
兼容 MySQL 语法,无需学更多方言 SQL,会 MySQL 语法即可
生态融合好,无论上游的数据集成组件,还是下游的BI报表组件,都有比较好的生态贯通
性能强大
全球范围内,开源 OLAP 数据库中,单表大宽表查询性能与 ClickHouse 为同一梯队
TPC-H 场景中,联邦查询能力比 Prosto 快 2-3 倍
联表 JOIN 场景中,性能为其他竞品的 1.5-2 倍
唯一一个有倒排索引覆盖 ES 场景的 OLAP 库
单 FE 在单表高并发点查场景下可以支持上万 QPS
等资源下,ELT 任务执行速度比 Hive On MR 快 8-10 倍,比 Hive On Spark 快 2-3 倍
等资源下,比 Impala + Kudu 组合快 3-4 倍
数据流转简单
支持 Flink、Kafka、Spark 等数据 ETL 引擎或者消息中间件
支持 HTTP API、LocalFile、Stream 等数据格式导入
支持 MySQL、Hive、ES、Oracle、ClickHouse 等常见数据库的外表挂载和导入
支持 Hudi、Iceberg、Paimon、Hive 等数据湖产品的生态融合
应用范围广
现代化实时数据平台
企业级报表展示平台
DMP/CDP 画像平台
日志检索查询平台
离线数仓加速平台
高并发单表/维表点查平台
强大的活跃社区
500+ 的 Contributor
月活跃 Contributor 100+
Stars 8350+
30+ 的官方微信社群,去重后 1w+ 参与人数
半个月到一个月的新版本迭代周期
SelectDB 组建了三四十人的社区支持团队做免费技术支持
BUG 响应及使用指导相应在小时级到分钟级
纯国产化的数据库
完全由国人自主研发
完善的中文文档
成熟的各个场景解决方案
常见适用场景

场景浅析
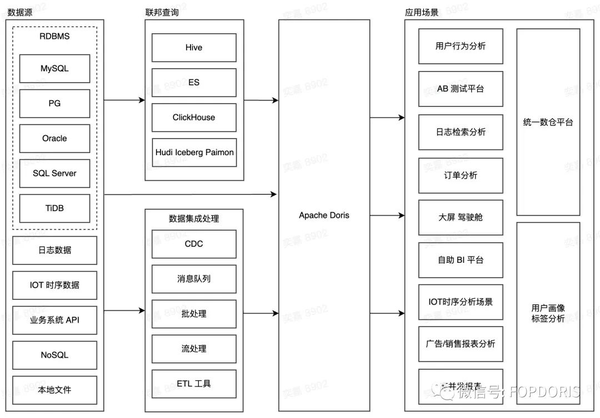
Apache Doris 在整个数据流中的位置
1. OLAP 分析引擎库(大宽表场景)
OLAP 分析引擎库,一般要选用在单表查询方向能力比较强的数据库,比如 ClickHouse、Druid 等,ClickHouse 本身是一款非常优秀的 MPP 数据库,在大宽表的查询领域可谓长期独领风骚,但是自从去年 Apache Doris 完成了全面向量化以后,ClickHouse 就遇到了一生之敌也是一生挚友。
同样用的 MPP 架构 + 向量化引擎的底层,看的就是哪家在细节上做的更好了,在去年十一期间,社区参与了 ClickHouse 发起的 OLAP 领域天梯榜 ClickBench,成功拿下全球性能第一的位置,并在再未重新打榜的基础上在榜首待了四个月多月。
综上,Doris 在 OLAP 大宽表分析场景里,比 ClickHouse 具有优势的地方在于易用性、易维护性和高拓展性,水平拓展后无需手动 reblance 即可完成数据的重负载,还有类似 HDFS 的强大三副本自愈能力等。
2. 日志检索引擎库
在传统的日志检索过程中,一般选用 ElasticSearch 作为存储和分析库,除去在搜索引擎里使用 ElasticSearch 强大的分词能力和联想能力以外,在大部分使用场景中,还是以核心的文本类型全文检索为常用使用方式,所以 Doris 用 Loki 为代表的轻量索引/无索引架构,设计了倒排索引和全文检索特性。
这样在只需要核心文本类型做全文检索和倒排索引的场景里,一来导入不需要再占据大量的附加索引空间,二来可以提升导入的时效性和效率,三来可以使用标准 SQL 进行半结构化数据的查询,同时还能将日志数据和其他业务数据或者维度数据进行关联,无需再进行导数同步,同时支持半结构化数据直接入库。
用 ElasticSearch 的官方数据测试集测试后,Doris 的存储成本相较 ElasticSearch 下降 80%,倒排索引场景查询速度快 2.3 倍,导入速度快 4.2 倍。
3. 单表高并发点查引擎库
在企业应用中,一般会有两种场景比较常见单表高并发点查,一种是将该库用于维表关联,可能会有高 QPS 的单表查询场景,还有一种是将该库直接提供给业务系统进行使用,这种场景下要求数据库必须满足整个系统工程的压力。
无论是第一种还是第二种,业界对于单报表高并发点查场景的数据库选型,一般是用 Redis 和 Hbase,比如在面向企业广告主、或者是面向运营商消费用户而言的高并发查询场景里,一般是一个明细表要进行各种过滤和聚合,比如要查一段时间内的广告投放金额、一段时间内的话费消费情况等。
由于一般做 ETL 计算是上游数据仓库做的,所以往往这份数据需要在数据仓库存一份,再在单报表高并发点查引擎库里存一份,一方面数据有冗余性,存储成本变大,另一方面数据链路变长,治理难度加大,数据时效性变低。
综上,Doris 2.0 采用了行列混存数据存储模式,单 FE 可支持上万 QPS 的单报表高并发点查,完美适配这一场景。
4. 用户画像引擎库
用户画像一般面临的问题有两个,一个是要极速的预估,一个是要快速的出包。
预估的速度决定了业务使用方在使用过程中是否可以体感比较好的完成业务诉求,而出包(人群包)的速度决定了整个画像链路在触达时候的时效性。
这一块 Doris 已经有非常多的成熟案例了,诸如腾讯音乐 DMP、知乎 DMP等案例,可谓是业界的标杆级案例了。
究其底层呢,主要是在 bitmap 位图索引上的大规模专项优化,包括函数和索引本身。以及为了适配画像圈选大宽表的不确定性,还做了动态 Schema Change 的能力,极大的降低数据开发过程中的难度和使用难度。
以知乎为例(0.15非向量化版本),6台机器,撑起了1100亿用户数据、750个标签组、250万标签值的画像查询任务,在 1000 个圈选条件下达到了 1s 出预估人群数,10个圈选条件下 1s 出人群包的极致速度。
5. AdHoc 分析引擎库
在企业日常内部场景中,AdHoc 场景随着大数据的发展变得越来越常见了。
这个场景里,主打的是数据分析同学的自由编排能力,考验的是底层引擎库的查询能力、分布式 Join 能力以及 CBO + RBO 优化能力。而早在 Doris 立项之初,本身就是为了解决百度内部报表问题的,所以在这个场景里可谓磨炼了十年的最擅长的场景了。
Doris 是 MPP 架构的全面向量化引擎加持下的实时数据仓库,在 2.0 会推出新的 CBO 和 RBO,所以这一场景无需赘述,选它就一定可以得到性能加速~
6. 统一网关平台
在湖仓并行时代里,企业往往会使用大量的组件来分门别类的完成不同场景的应用,比如使用 Hive 构建离线数仓、使用 Hbase 完成高并发点查、使用 ClickHouse 完成 OLAP 大宽表极速查询、使用 Impala + Kudu 完成 AdHoc 查询等等,那么在这么多组件的情况下,想要拿 MySQL 里的一个表的数据关联 Hbase 里的一个表的数据时,必须得把数据同步到一个库内,或者再加一层 Presto 组件来统一网关层。
在这样的复杂度情况下,组件越多意味着风险越高,稳定性越差,所以 Doris 本身自带了联邦查询模块,可以有效平替 Presto 的应用场景,性能还要优于 Presto 2-3 倍。
基于这一点,Doris 在复杂系统架构引入过程中,还可以采用非侵入式的引入,这样就极大的降低了企业架构迭代过程中的痛苦,可以无感的进行架构升级和平台能力升级。
7. 实时数仓
实时数仓这个命题在很多场景都是伪命题,因为如果想要真做到实时数仓,必须要在导入、存储、查询这三块都要做到实时,才算是实时仓库。
当前业界主流的实时化平台是 Flink + Kafka 组合,这个组合有一定的缺点,就是本身的计算消耗资源比较大,出的指标比较固定,且还要解决很多业务上的诸如数据迟到、丢失等问题。
Doris 自身是保证导入事务性的,当前支持微批次的导入,在1台 8C32G 机器做 Flink 节点、3台 16C64G 机器做 Doris 集群的情况下,压测可达到 20w/s 的导入速度,同时 Doris 的导入事务就保证了但凡插入成功的数据批次,就一定是实时可见的。
同时 Doris 本身的物化视图、索引等落盘数据,都是包含在导入事务控制里的,所以可以做到不丢不重且实时可见性,而且 Doris 还提供了 AGG 聚合模型和 Unique 主键模型,在部分指标计算场景里可以利用 AGG 模型来完成指标聚合计算,导入即计算完成,无需额外调度。
在2.0版本里,已经开发完成全量级的多表物化视图,预计2.1版本会开发完增量级的多表物化视图,届时 Apache Doris 的实时数仓场景将迎来蜕变级的新生!
8. 现代化数据平台
关于数据平台这个概念,我认为应当是集合了如上众多能力的一个综合体,可以给企业内部做报表分析,可以给业务系统提供查询支持,可以通过埋点日志进行实时分析,可以为指标看板/BI工具等上层应用提供支持,可以做 ETL/ELT 的离线加工等等,而 Apache Doris,就是一个集百家之长又专心于 OLAP 数据库本身的一款实时数据仓库。
Doris 的内表在和 Hive 等规模的情况下进行 ELT/ETL 任务对比时,Hive On MR 综合执行时间是 Doris 的8-10倍,Hive On Spark 综合执行时长是 Doris 的2-3倍,在新版本里还会有保障 ETL/ELT 的三个特性来让跑的更快、更稳。
所以如果中小企业选型,可以选择 All In Apache Doris~
小结
Apache Doris 作为一款国产的 OLAP 数据库,在当前国内开源界的影响力是与日俱增的,越来越多的中小企业选择 All In Doris 作为自己的数据平台,也有众多大企业选用 Doris 来解决不同业务线的重要问题,随着 Apache Doris 的进一步发展,一定是可以带给更多的企业和个人带来生产力的提升和成本的下降。
所以还在等什么?速速联系我加入到 Apache Doris 官方社区群里开始一起玩耍呀!来感受和体验一下最火热的开源社区的热情和迭代速度吧!