
Python爬虫(二)–Coursera抓站小结
继豆瓣抓站后再对Coursera下手
系统:Mac OS X 10.10.1
编辑器: Sublime Text2
Python版本: 2.7.8
模块依赖: import sys, string, re, random, urllib, urllib2, cookielib, getpass(均为系统内的模块)
0. 抓站小结
0.1. cookie处理
需要进行登陆的时候, 要进行cookie的处理,使用以下方法
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
req = urllib2.Request(url)
content = urllib2.urlopen(req)0.2. 表单处理
某些网站需要进行账户和密码登陆, 需要使用POST方法向服务器发送账户和密码表单数据, 这里就需要模拟登陆.
如何获取表单数据的格式呢?
通过谷歌浏览器开发者工具中Network锁定请求头部和post发出的表单数据,伪装表单数据
当由于Method太多, 找不到POST提交登录请求Method方法的时候, 可以尝试使用错误密码, 这样就可以容易的找POST方法对应的头部.
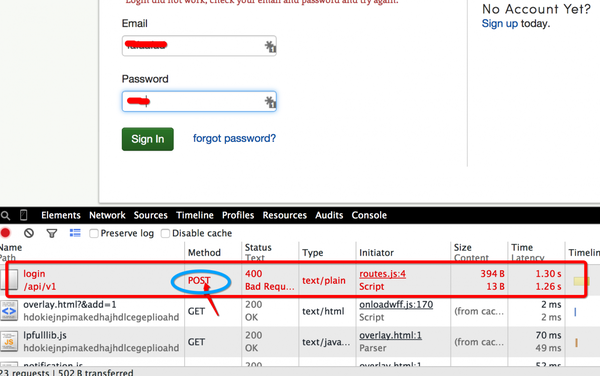
找到POST方法
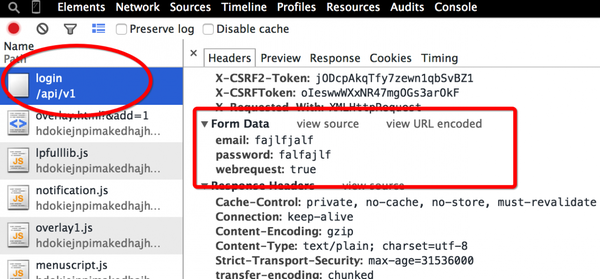
表单处理
form_data = urllib.urlencode({ #注意urlencode方法
\"email\": self.user_name,
\"password\": self.password,
\"webrequest\": \"true\"
})0.3. 防盗链和伪装成浏览器访问
防盗链就是需要在请求的头部加入Referer字段, Referer 指的是HTTP头部的一个字段, 用来表示从哪儿链接到目前的网页,采用的格式是URL。换句话说,借着 HTTP Referer 头部网页可以检查访客从哪里而来,这也常被用来对付伪造的跨网站请求。
伪装成浏览器就是将User-Agent设置为浏览器的字段
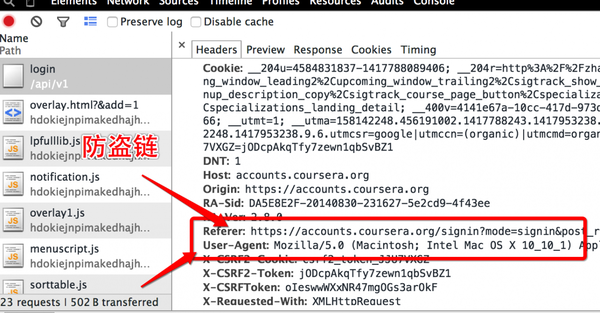
伪装头部
user_agent = (\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) \"
\"AppleWebKit/537.36 (KHTML, like Gecko) \"
\"Chrome/38.0.2125.111 Safari/537.36\")
request_header = {
\"Referer\": \"https://accounts.coursera.org/signin\", #对付防盗链设置, 为跳转来源的url
\"User-Agent\": user_agent, #伪装成浏览器访问
}1. 伪装头部
使用谷歌浏览器自带的开发者工具, 选择Network(Element用来查看网站源码等功能), 获取详细的GET和POST方法, 从中获取登录请求的的头部信息,
从POST中获得Headers信息如下(省略部分不重要信息)
Request URL:https://accounts.coursera.org/api/v1/login //真正的登陆验证页面
Request Method:POST
Status Code:401 Unauthorized
//Request Headers
Connection:keep-alive
Content-Length:55
Content-Type:application/x-www-form-urlencoded
Cookie:(省略cookie信息, 下面详细介绍)
...
Referer:https://accounts.coursera.org/signin //防盗链设置
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36 //浏览器浏览标识
//下面四行为服务器所做的限制字段
X-CSRF2-Cookie:csrf2_token_el67QDLg
X-CSRF2-Token:1oxZDVMuZGX0qCggdReQyj2R
X-CSRFToken:WnVtiMDpvw0JXJqHjPrFk0EU
X-Requested-With:XMLHttpRequest
//Form Data
email:1095...@qq.com //Coursera账户信息
password:FAFA //账户密码
webrequest:true //固定字段这样就能写出模拟头部的函数
def structure_headers(self) :
#模拟表单数据,这个参数不是字典
form_data = urllib.urlencode({
\"email\": self.user_name,
\"password\": self.password,
\"webrequest\": \"true\"
})
user_agent = (\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) \"
\"AppleWebKit/537.36 (KHTML, like Gecko) \"
\"Chrome/38.0.2125.111 Safari/537.36\")
request_header = {
\"Referer\": \"https://accounts.coursera.org/signin\", #对付防盗链设置, 为跳转来源的url
\"User-Agent\": user_agent, #伪装成浏览器访问
}
return form_data, request_header试了几次竟然都是400错误, 也就是头部请求的格式不正确, 通过多次Headers查看, 发现有下面四处不同的头部
X-CSRF2-Cookie:csrf2_token_hTu4Zy8Y 最后八位不同
X-CSRF2-Token:O5OIRan9I99lTHmnYS27ocYb 完全随机
X-CSRFToken:HClYbs9HZoGweU54iR5r5z2y 完全随机
X-Requested-With:XMLHttpRequest 固定不变通过放上搜索找到了解决方案, coursera的请求头部中
X-CSRF2-Token和X-CSRFToken是完全随机的,X-CSRF2-Cookie后八位是随机生成的, 都是由字母和数字随机生成的.
于是修改代码如下:
def structure_headers(self) :
#模拟表单数据,这个参数不是字典
form_data = urllib.urlencode({
\"email\": self.user_name,
\"password\": self.password,
\"webrequest\": \"true\"
})
user_agent = (\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) \"
\"AppleWebKit/537.36 (KHTML, like Gecko) \"
\"Chrome/38.0.2125.111 Safari/537.36\")
XCSRF2Cookie = \'csrf2_token_%s\' % \'\'.join(self.random_string(8))
XCSRF2Token = \'\'.join(self.random_string(24))
XCSRFToken = \'\'.join(self.random_string(24))
cookie = \"csrftoken=%s; %s=%s\" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
request_header = {
\"Referer\": \"https://accounts.coursera.org/signin\", #对付防盗链设置, 为跳转来源的url
\"User-Agent\": user_agent, #伪装成浏览器访问
\"X-Requested-With\": \"XMLHttpRequest\",
\"X-CSRF2-Cookie\": XCSRF2Cookie,
\"X-CSRF2-Token\": XCSRF2Token,
\"X-CSRFToken\": XCSRFToken,
\"Cookie\": cookie
}
return form_data, request_header
def random_string(self, length):
return \'\'.join(random.choice(string.letters + string.digits) for i in xrange(length))2. 模拟登陆
登陆coursra的下载页面时计算机组成视频下载, 会发现是要求登陆呢, 这时候就使用cookielib模块进行cookie的处理
def simulation_login(self) :
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
form_data, request_header = self.structure_headers()
req = urllib2.Request(self.login_url, data = form_data, headers = request_header)
try :
result = urllib2.urlopen(req)
except urllib2.URLError,e :
if hasattr(e, \"code\"):
print \"The server couldn\'t fulfill the request.Please check your url and read the Reason\"
print \"Error code: %s\" % e.code
elif hasattr(e, \"reason\"):
print \"We failed to reach a server. Please check your url and read the Reason\"
print \"Reason: %s\" % e.reason
sys.exit(2)
if result.getcode() == 200 :
print \"登陆成功...\"这个函数用于模拟登陆, 并显示登陆成功或者失败
3. 抓取下载链接
抓取链接通过正则表达式, 主要匹配PDF下载链接和MP4视频下载链接
使用re.findall()函数进行函数匹配
def get_links(self) :
try :
result = urllib2.urlopen(self.url)
except urllib2.URLError,e :
if hasattr(e, \"code\"):
print \"The server couldn\'t fulfill the request.\"
print \"Error code: %s\" % e.code
elif hasattr(e, \"reason\"):
print \"We failed to reach a server. Please check your url and read the Reason\"
print \"Reason: %s\" % e.reason
sys.exit(2)
content = result.read().decode(\"utf-8\")
print \"读取网页成功...\"
down_links = re.findall(r\'4. 写入完本
既然已经匹配了所有的链接, 这一步就是将链接写入到文件中
def start_spider(self) :
self.simulation_login()
down_links, down_pdfs = self.get_links()
with open(\"coursera.html\", \"w+\") as my_file :
print \"下载链接的长度\", len(down_links)
for link in down_links :
print link
try :
my_file.write(link + \"\\n\")
except UnicodeEncodeError:
sys.exit(2)
with open(\"coursera.pdf\", \"w+\") as my_file :
print \"下载pdf的长度\", len(down_pdfs)
for pdf in down_pdfs :
try :
my_file.write(pdf + \"\\n\")
except UnicodeEncodeError :
sys.exit(2)
print \"抓取Coursera课程下载链接和pdf链接成功\"5. 登陆调用
使用getpass模块中的getpass()输入密码, 使用这个函数输入密码的时候不会显示任何字符, 貌似体验不好, 下次修改一下, 然后命令行传入下载课程的参数.
通过比较每门课下载页面, 发现之后/lecture前的这个字段是不同的,这样可以设置通过命令行传入这这个参数
https://class.coursera.org/pkuco-001/lecture
https://class.coursera.org/electromagnetism-001/lecture
这里在运行命令行只需要传入
pkuco-001或者electromagnetism-001这种字段
def main() :
if len(sys.argv) != 2 :
print \"Please Input what course you want to download..\"
sys.exit(2)
url = \"https://class.coursera.org/{course}/lecture\"
user_name = raw_input(\"Input your Email > \")
password = getpass.getpass(\"Input your Password > \")
spider = Coursera(url.format(course = sys.argv[1]), user_name, password)
spider.start_spider()6. 下载脚本
下载可以使用curl, Mac下安装方法
brew install curl编写下载使用的Python脚本, 编写成功后, 修改脚本文件的文件权限
chmod 755 downloadshell.py #最后一个参数为Python脚本名称运行下载脚本
$python downloadshell.py coursera.pdf #最后一个参数为连接保存文件下面是我自己编写的简单的下载脚本
#!/usr/bin/python2
# -*- coding:utf-8 -*-
#简单的文件下载脚本
import os
import sys, re
def read_file(file_name) :
down_links = []
with open(file_name, \"r\") as my_file :
for url in my_file :
down_links.append(url.replace(\"\\n\", \"\"))
return down_links
def main() :
if len(sys.argv) != 2 :
print \"Please input file name...\"
sys.exit(2)
down_links = read_file(sys.argv[1])
pdf_index = 1
mp4_index = 1
for index, link in enumerate(down_links) :
if link.find(\"mp4\") != -1 :
os.system(\"curl \" + link + \" -o \" + \"%d.mp4\" % mp4_index)
elif link.find(\"pdf\") != -1 :
os.system(\"curl \" + link + \" -o \" + \"%d.pdf\" % pdf_index)
pdf_index += 1
else :
print \"请自行补全下载命令...\"
if __name__ == \'__main__\':
main()7.完整代码查看
Github完整代码