
浅析Python中的多条件排序实现
admin
2023-08-02 06:23:41
0次
多条件排序及itemgetter的应用
曾经客户端的同事用as写一大堆代码来排序,在得知Python排序往往只需要一行,惊讶无比,遂对python产生浓厚的兴趣。
之前在做足球的积分榜的时候需要用到多条件排序,如果积分相同,则按净胜球,再相同按进球数,再相同按失球数。
即按积分P、净胜球GD、进球GS、失球GA这样的顺序。
在python中,排序非常方便,排序的参数主要有key、reverse。参数cmp不建议使用了,在python3.0被移除了,用参数key代替。
对于多条件排序,也非常简单,只需要记住下面这句话就行。 即参数key指定的函数返回一个元组,多条件排序的顺序将按照元组的顺序。
看了下面的代码你就明白了,下面是2010世界杯小组赛A组的积分榜。
teamitems = [{\'team\':\'France\' , \'P\':1 , \'GD\':-3 , \'GS\':1 , \'GA\':4},
{\'team\':\'Uruguay\' , \'P\':7 , \'GD\':4 , \'GS\':4 , \'GA\':0},
{\'team\':\'SouthAfrica\' , \'P\':4 , \'GD\':-2 , \'GS\':3 , \'GA\':5},
{\'team\':\'Mexico\' , \'P\':4 , \'GD\':1 , \'GS\':3 , \'GA\':2}]
print sorted(teamitems ,key = lambda x:(x[\'P\'],x[\'GD\'],x[\'GS\'],x[\'GA\']),reverse=True)
输出
[{\'P\': 7, \'GD\': 4, \'GS\': 4, \'GA\': 0, \'team\': \'Uruguay\'},
{\'P\': 4, \'GD\': 1, \'GS\': 3, \'GA\': 2, \'team\': \'Mexico\'},
{\'P\': 4, \'GD\': -2, \'GS\': 3, \'GA\': 5, \'team\': \'SouthAfrica\'},
{\'P\': 1, \'GD\': -3, \'GS\': 1, \'GA\': 4, \'team\': \'France\'}]
即小组排名是乌拉圭、墨西哥、南非、法国。
不过这样一个个取字典的键值有点啰嗦,用itemgetter更简洁优雅,上面那句代码可以用如下替换。
from operator import itemgetter print sorted(teamitems ,key = itemgetter(\'P\',\'GD\',\'GS\',\'GA\'),reverse=True)
有的升序有的降序的情况下怎么多条件排序
之前在统计导出各区服玩家消费的时候需要进行升序降序混搭的多条件排序。
需求是这样的。区服从小到大排,如果区服相同,则按消费从大到小排。
实现方法是利用python的sort算法是稳定排序,对数据进行多次排序,先排次要条件,后排主要条件。
还有一种更简洁的一行流的方法,不过只有当待排数据是数值的时候才有效。此方法利用相反数的性质,在前面加个负号。
下面上代码。
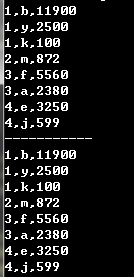
#假设数据如下。 data = \'\'\'\'\' 区服,玩家id,累积消费 3,a,2380 1,b,11900 4,e,3250 1,k,100 4,j,599 2,m,872 3,f,5560 1,y,2500 \'\'\' items = [x.split(\',\') for x in filter(None,data.split(\'\\n\'))[1:]] #去掉空行和忽略首行并把字符串转成二维数组 #方法一 items.sort(key=lambda x:int(x[2]),reverse=True)#先排消费 items.sort(key=lambda x:int(x[0]))#然后排区服 print \'\\n\'.join([\',\'.join(x) for x in items]) print \'-----------\' #方法二 items = sorted(items,key=lambda x:(int(x[0]),-int(x[2]))) print \'\\n\'.join([\',\'.join(x) for x in items])
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...