
利用Python爬取可用的代理IP
admin
2023-08-01 15:27:00
0次
前言
就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/。在使用的时候发现很多IP都用不了。
所以用Python写了个脚本,该脚本可以把能用的代理IP检测出来。
脚本如下:
#encoding=utf8
import urllib2
from bs4 import BeautifulSoup
import urllib
import socket
User_Agent = \'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0\'
header = {}
header[\'User-Agent\'] = User_Agent
\'\'\'
获取所有代理IP地址
\'\'\'
def getProxyIp():
proxy = []
for i in range(1,2):
try:
url = \'http://www.xicidaili.com/nn/\'+str(i)
req = urllib2.Request(url,headers=header)
res = urllib2.urlopen(req).read()
soup = BeautifulSoup(res)
ips = soup.findAll(\'tr\')
for x in range(1,len(ips)):
ip = ips[x]
tds = ip.findAll(\"td\")
ip_temp = tds[1].contents[0]+\"\\t\"+tds[2].contents[0]
proxy.append(ip_temp)
except:
continue
return proxy
\'\'\'
验证获得的代理IP地址是否可用
\'\'\'
def validateIp(proxy):
url = \"http://ip.chinaz.com/getip.aspx\"
f = open(\"E:\\ip.txt\",\"w\")
socket.setdefaulttimeout(3)
for i in range(0,len(proxy)):
try:
ip = proxy[i].strip().split(\"\\t\")
proxy_host = \"http://\"+ip[0]+\":\"+ip[1]
proxy_temp = {\"http\":proxy_host}
res = urllib.urlopen(url,proxies=proxy_temp).read()
f.write(proxy[i]+\'\\n\')
print proxy[i]
except Exception,e:
continue
f.close()
if __name__ == \'__main__\':
proxy = getProxyIp()
validateIp(proxy)
运行成功后,打开E盘下的文件,可以看到如下可用的代理IP地址和端口:
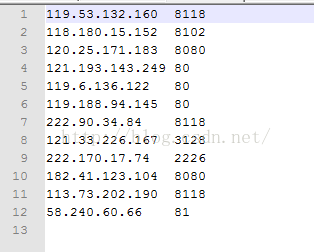
总结
这只是爬取的第一页的IP地址,如有需要,可以多爬取几页。同时,该网站是时时更新的,建议爬取时只爬取前几页的即可。以上就是本文的全部内容,希望对大家学习使用Python能有所帮助。
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...