
Python爬虫爬取美剧网站的实现代码
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷下载的美剧下载网站【天天美剧】,各种资源随便下载,最近迷上的BBC的高清纪录片,大自然美得不要不要的。
虽说找到了资源网站可以下载了,但是每次都要打开浏览器,输入网址,找到该美剧,然后点击链接才能下载。时间长了就觉得过程好繁琐,而且有时候网站链接还会打不开,会有点麻烦。正好一直在学习Python爬虫,所以今天就心血来潮来写了个爬虫,抓取该网站上所有美剧链接,并保存在文本文档中,想要哪部剧就直接打开复制链接到迅雷就可以下载啦。
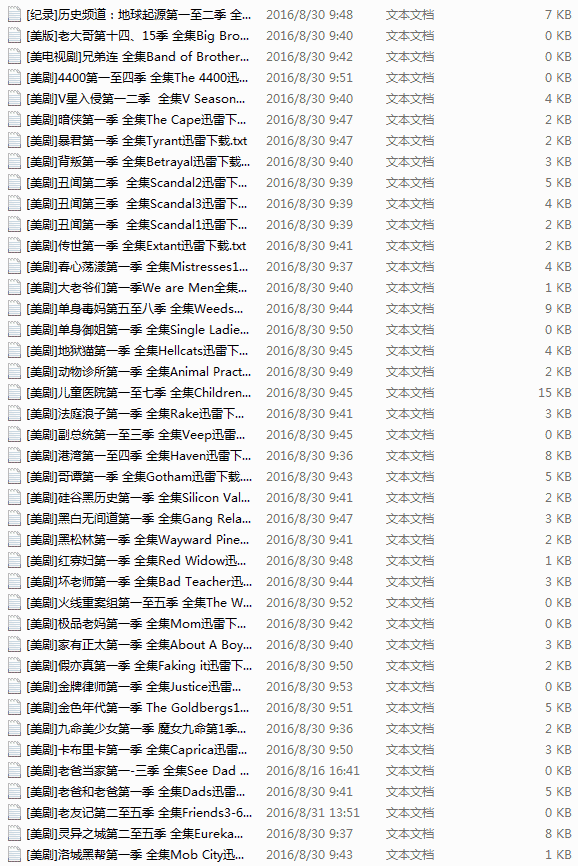
其实一开始打算写那种发现一个url,使用requests打开抓取下载链接,从主页开始爬完全站。但是,好多重复链接,还有其网站的url不是我想的那么规则,写了半天也没有写出我想要的那种发散式的爬虫,也许是自己火候还不到吧,继续努力。。。
后来发现,其电视剧链接都是在文章里面,然后文章url后面有个数字编号,就像这样的http://cn163.net/archives/24016/,所以机智的我又用了之前写过的爬虫经验,解决方法就是自动生成url,其后面的数字不是可以变的吗,而且每部剧的都是唯一的,所以尝试了一下大概有多少篇文章,然后用range函数直接连续生成数来构造url。
但是很多url是不存在的,所以会直接挂掉,别担心,我们用的可是requests,其自带的status_code就是用来判断请求返回的状态的,所以只要是返回的状态码是404的我们都把它跳过,其他的都进去爬取链接,这就解决了url的问题了。
以下就是上述步骤的实现代码。
def get_urls(self):
try:
for i in range(2015,25000):
base_url=\'http://cn163.net/archives/\'
url=base_url+str(i)+\'/\'
if requests.get(url).status_code == 404:
continue
else:
self.save_links(url)
except Exception,e:
pass
其余的就进行的很顺利了,网上找到前人写的类似的爬虫,但是只是爬取一篇文章的,所以借鉴了一下其正则表达式。自己用了BeautifulSoup还没有正则效果好,所以果断弃了,学海无涯啊。但是效果也不是那么理想,有一半左右的链接不能正确抓取,还需继续优化。
# -*- coding:utf-8 -*-
import requests
import re
import sys
import threading
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
class Archives(object):
def save_links(self,url):
try:
data=requests.get(url,timeout=3)
content=data.text
link_pat=\'\"(ed2k://\\|file\\|[^\"]+?\\.(S\\d+)(E\\d+)[^\"]+?1024X\\d{3}[^\"]+?)\"\'
name_pat=re.compile(r\'(.*?)
\',re.S)
links = set(re.findall(link_pat,content))
name=re.findall(name_pat,content)
links_dict = {}
count=len(links)
except Exception,e:
pass
for i in links:
links_dict[int(i[1][1:3]) * 100 + int(i[2][1:3])] = i#把剧集按s和e提取编号
try:
with open(name[0].replace(\'/\',\' \')+\'.txt\',\'w\') as f:
print name[0]
for i in sorted(list(links_dict.keys())):#按季数+集数排序顺序写入
f.write(links_dict[i][0] + \'\\n\')
print \"Get links ... \", name[0], count
except Exception,e:
pass
def get_urls(self):
try:
for i in range(2015,25000):
base_url=\'http://cn163.net/archives/\'
url=base_url+str(i)+\'/\'
if requests.get(url).status_code == 404:
continue
else:
self.save_links(url)
except Exception,e:
pass
def main(self):
thread1=threading.Thread(target=self.get_urls())
thread1.start()
thread1.join()
if __name__ == \'__main__\':
start=time.time()
a=Archives()
a.main()
end=time.time()
print end-start
完整版代码,其中还用到了多线程,但是感觉没什么用,因为Python的GIL的缘故吧,看似有两万多部剧,本以为要很长时间才能抓取完成,但是除去url错误的和没匹配到的,总共抓取时间20分钟不到。搞得我本来还想使用Redis在两台Linux上爬取,但是折腾了一番之后感觉没必要,所以就这样吧,后面需要更大数据的时候再去弄。
还有过程中遇到一个很折磨我的问题是文件名的保存,必须在此抱怨一下,txt文本格式的文件名能有空格,但是不能有斜线、反斜线、括号等。就是这个问题,一早上的时间都花在这上面的,一开始我以为是抓取数据的错误,后面查了半天才发现是爬取的剧名中带有斜杠,这可把我坑苦了。
本文作者:码农网 – 肖豪
下一篇:Python选课系统开发程序