
用Python写一个简单的微博爬虫
我是个微博重度用户,工作学习之余喜欢刷刷timeline看看有什么新鲜事发生,也因此认识了不少高质量的原创大V,有分享技术资料的,比如好东西传送门;有时不时给你一点人生经验的,比如石康;有高产的段子手,比如银教授;有黄图黄段子小能手,比如阿良哥哥 木木萝希木 初犬饼…
好吧,我承认,爬黄图黄段子才是我的真实目的,前三个是掩人耳目的…(捂脸,跑开)
另外说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下:

只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF!
所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少。
最后实现的功能:
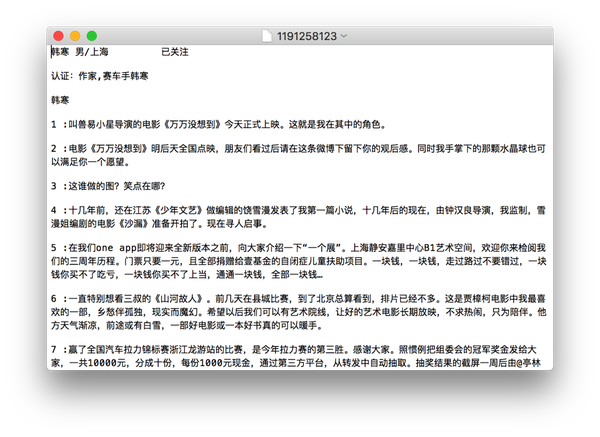
- 输入要爬取的微博用户的user_id,获得该用户的所有微博
- 文字内容保存到以%user_id命名文本文件中,所有高清原图保存在weibo_image文件夹中
具体操作:
首先我们要获得自己的cookie,这里只说chrome的获取方法。
- 用chrome打开新浪微博移动端
option+command+i调出开发者工具- 点开
Network,将Preserve log选项选中 - 输入账号密码,登录新浪微博
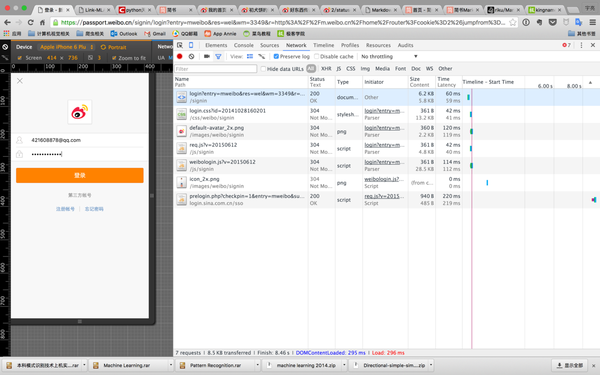
- 找到
m.weibo.cn->Headers->Cookie,把cookie复制到代码中的#your cookie处
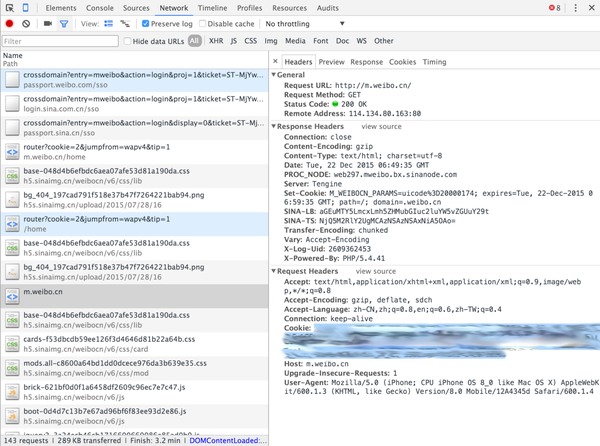
cookie
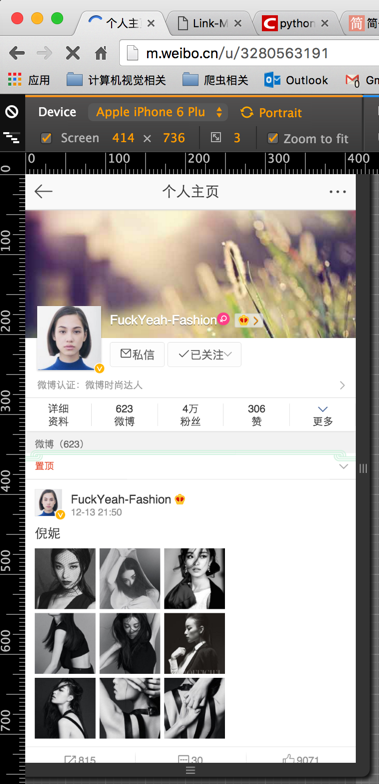
然后再获取你想爬取的用户的user_id,这个我不用多说啥了吧,点开用户主页,地址栏里面那个号码就是user_id
将python代码保存到weibo_spider.py文件中
定位到当前目录下后,命令行执行python weibo_spider.py user_id
当然如果你忘记在后面加user_id,执行的时候命令行也会提示你输入
最后执行结束
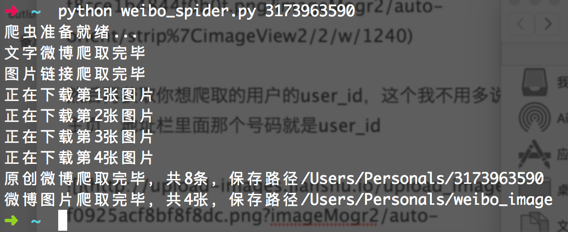
iTerm
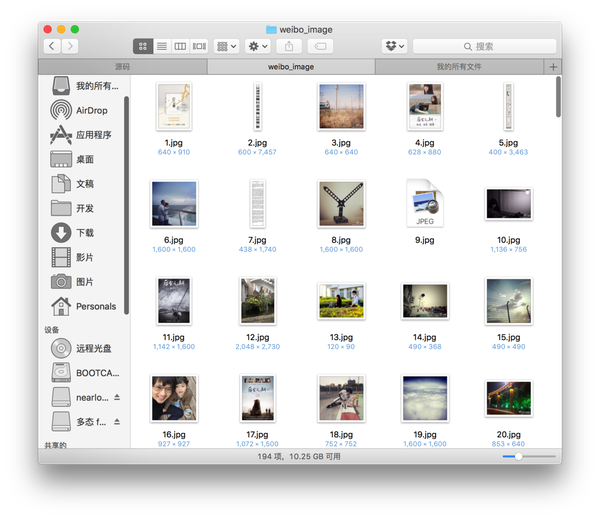
小问题:在我的测试中,有的时候会出现图片下载失败的问题,具体原因还不是很清楚,可能是网速问题,因为我宿舍的网速实在太不稳定了,当然也有可能是别的问题,所以在程序根目录下面,我还生成了一个userid_imageurls的文本文件,里面存储了爬取的所有图片的下载链接,如果出现大片的图片下载失败,可以将该链接群一股脑导进迅雷等下载工具进行下载。
另外,我的系统是OSX EI Capitan10.11.2,Python的版本是2.7,依赖库用sudo pip install XXXX就可以安装,具体配置问题可以自行stackoverflow,这里就不展开讲了。
下面我就给出实现代码(严肃脸)
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990 | #-*-coding:utf8-*- import reimport stringimport sysimport osimport urllibimport urllib2from bs4 import BeautifulSoupimport requestsfrom lxml import etree reload(sys) sys.setdefaultencoding(\’utf-8\’)if(len(sys.argv) >=2): user_id = (int)(sys.argv[1])else: user_id = (int)(raw_input(u\”请输入user_id: \”)) cookie = {\”Cookie\”: \”#your cookie\”}url = \’http://weibo.cn/u/%d?filter=1&page=1\’%user_id html = requests.get(url, cookies = cookie).contentselector = etree.HTML(html)pageNum = (int)(selector.xpath(\’//input[@name=\”mp\”]\’)[0].attrib[\’value\’]) result = \”\” urllist_set = set()word_count = 1image_count = 1 print u\’爬虫准备就绪…\’ for page in range(1,pageNum+1): #获取lxml页面 url = \’http://weibo.cn/u/%d?filter=1&page=%d\’%(user_id,page) lxml = requests.get(url, cookies = cookie).content #文字爬取 selector = etree.HTML(lxml) content = selector.xpath(\’//span[@class=\”ctt\”]\’) for each in content: text = each.xpath(\’string(.)\’) if word_count >= 4: text = \”%d :\”%(word_count–3) +text+\”\\n\\n\” else : text = text+\”\\n\\n\” result = result + text word_count += 1 #图片爬取 soup = BeautifulSoup(lxml, \”lxml\”) urllist = soup.find_all(\’a\’,href=re.compile(r\’^http://weibo.cn/mblog/oripic\’,re.I)) first = 0 for imgurl in urllist: urllist_set.add(requests.get(imgurl[\’href\’], cookies = cookie).url) image_count +=1 fo = open(\”/Users/Personals/%s\”%user_id, \”wb\”)fo.write(result)word_path=os.getcwd()+\’/%d\’%user_idprint u\’文字微博爬取完毕\’ link = \”\”fo2 = open(\”/Users/Personals/%s_imageurls\”%user_id, \”wb\”)for eachlink in urllist_set: link = link + eachlink +\”\\n\”fo2.write(link)print u\’图片链接爬取完毕\’ if not urllist_set: print u\’该页面中不存在图片\’else: #下载图片,保存在当前目录的pythonimg文件夹下 image_path=os.getcwd()+\’/weibo_image\’ if os.path.exists(image_path) is False: os.mkdir(image_path) x=1 for imgurl in urllist_set: temp= image_path + \’/%s.jpg\’ % x print u\’正在下载第%s张图片\’ % x try: urllib.urlretrieve(urllib2.urlopen(imgurl).geturl(),temp) except: print u\”该图片下载失败:%s\”%imgurl x+=1 print u\’原创微博爬取完毕,共%d条,保存路径%s\’%(word_count–4,word_path)print u\’微博图片爬取完毕,共%d张,保存路径%s\’%(image_count–1,image_path) |
下一篇:逐步提升程序质量的演变过程示例