
Python编写的最短路径算法
admin
2023-07-31 00:38:01
0次
一心想学习算法,很少去真正静下心来去研究,前几天趁着周末去了解了最短路径的资料,用python写了一个最短路径算法。算法是基于带权无向图去寻找两个点之间的最短路径,数据存储用邻接矩阵记录。首先画出一幅无向图如下,标出各个节点之间的权值。
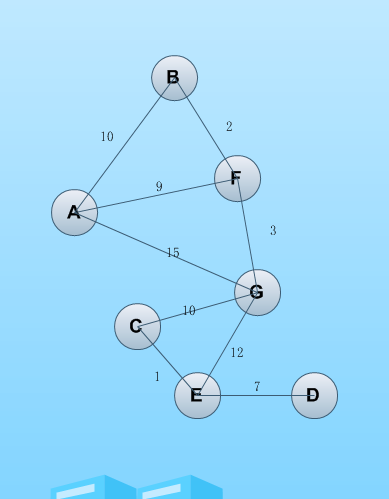
其中对应索引:
A ——> 0
B——> 1
C——> 2
D——>3
E——> 4
F——> 5
G——> 6
邻接矩阵表示无向图:
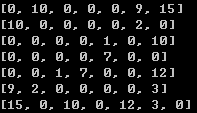
算法思想是通过Dijkstra算法结合自身想法实现的。大致思路是:从起始点开始,搜索周围的路径,记录每个点到起始点的权值存到已标记权值节点字典A,将起始点存入已遍历列表B,然后再遍历已标记权值节点字典A,搜索节点周围的路径,如果周围节点存在于表B,比较累加权值,新权值小于已有权值则更新权值和来源节点,否则什么都不做;如果不存在与表B,则添加节点和权值和来源节点到表A,直到搜索到终点则结束。
这时最短路径存在于表A中,得到终点的权值和来源路径,向上递推到起始点,即可得到最短路径,下面是代码:
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960 | # -*-coding:utf-8 -*-class DijkstraExtendPath(): def __init__(self, node_map): self.node_map = node_map self.node_length = len(node_map) self.used_node_list = [] self.collected_node_dict = {} def __call__(self, from_node, to_node): self.from_node = from_node self.to_node = to_node self._init_dijkstra() return self._format_path() def _init_dijkstra(self): self.used_node_list.append(self.from_node) self.collected_node_dict[self.from_node] = [0, –1] for index1, node1 in enumerate(self.node_map[self.from_node]): if node1: self.collected_node_dict[index1] = [node1, self.from_node] self._foreach_dijkstra() def _foreach_dijkstra(self): if len(self.used_node_list) == self.node_length – 1: return for key, val in self.collected_node_dict.items(): # 遍历已有权值节点 if key not in self.used_node_list and key != to_node: self.used_node_list.append(key) else: continue for index1, node1 in enumerate(self.node_map[key]): # 对节点进行遍历 # 如果节点在权值节点中并且权值大于新权值 if node1 and index1 in self.collected_node_dict and self.collected_node_dict[index1][0] > node1 + val[0]: self.collected_node_dict[index1][0] = node1 + val[0] # 更新权值 self.collected_node_dict[index1][1] = key elif node1 and index1 not in self.collected_node_dict: self.collected_node_dict[index1] = [node1 + val[0], key] self._foreach_dijkstra() def _format_path(self): node_list = [] temp_node = self.to_node node_list.append((temp_node, self.collected_node_dict[temp_node][0])) while self.collected_node_dict[temp_node][1] != –1: temp_node = self.collected_node_dict[temp_node][1] node_list.append((temp_node, self.collected_node_dict[temp_node][0])) node_list.reverse() return node_listdef set_node_map(node_map, node, node_lstdef set_node_map(node_map, node, node_lڄ最短路径,数据存储用邻接矩阵记录。首先画出一幅无向图如下,标出各个节点之间的权值。
其中对应索引: A ——> 0 B——> 1 C——> 2 D——>3 E——> 4 F——> 5 G——> 6 邻接矩阵表示无向图:
算法思想是通过Dijkstra算法结合自身想法实现的。大致思路是:从起始点开始,搜索周围的路径,记录每个点到起始点的权值存到已标记权值节点字典A,将起始点存入已遍历列表B,然后再遍历已标记权值节点字典A,搜索节点周围的路径,如果周围节点存在于表B,比较累加权值,新权值小于已有权值则更新权值和来源节点,否则什么都不做;如果不存在与表B,则添加节点和权值和来源节点到表A,直到搜索到终点则结束。 这时最短路径存在于表A中,得到终点的权值和来源路径,向上递推到起始点,即可得到最短路径,下面是代码:
|
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...