
复杂度为 O(1) 的「最不常用」缓存算法的 Python 实现
这篇文章描述了怎么用 Python 实现复杂度为 O(1) 的「最不常用」(Least Frequently Used, LFU)缓存回收算法。在 Ketan Shah、Anirban Mitra 和 Dhruv Matani的论文中有算法描述。实现中的命名是按照论文中的命名。
LFU 缓存回收机制对于 HTTP 缓存网络代理是非常有用的,我们可以从缓存中移除那些最不常使用的条目。
本文旨在设计一个其所有操作的时间复杂度都只有 O(1)的 LFU 缓存算法,这些操作包括了插入、访问和删除(回收)。
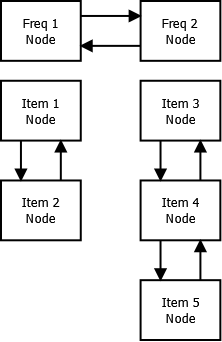
这个算法中用了双向链表。其一是用于访问频率,链表中的每个结点都包含一个链表,其中的元素有相同的访问频率。假设缓存中有5个元素。有两个元素被访问了一次,三个元素被访问了两次。在这个例子中,访问频率列表有两个结点(频率为1和2)。第一个频率结点的链表中有两个结点,第二个频率结点的链表中有三个结点。
我们要怎么构建它呢?我们需要的第一个对象是结点:
| 123456 | class Node(object): \”\”\”Node containing data, pointers to previous and next node.\”\”\” def __init__(self, data): self.data = data self.prev = None self.next = None |
接下来是双向链表。每个结点有 prev 和 next 属性,分别等于前一个和下一个结点。head 被设为第一个结点,tail 被设为最后一个结点。
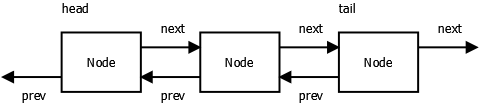
我们可以为双向链表定义方法来在链表尾部加入结点,插入结点,删除结点以及获得链表所有结点的数据。
| 12345678910111213141516171819202122232425262728293031323334353637383940414243444546 | class DoublyLinkedList(object): def __init__(self): self.head = None self.tail = None # Number of nodes in list. self.count = 0 def add_node(self, cls, data): \”\”\”Add node instance of class cls.\”\”\” return self.insert_node(cls, data, self.tail, None) def insert_node(self, cls, data, prev, next): \”\”\”Insert node instance of class cls.\”\”\” node = cls(data) node.prev = prev node.next = next if prev: prev.next = node if next: next.prev = node if not self.head or next is self.head: self.head = node if not self.tail or prev is self.tail: self.tail = node self.count += 1 return node def remove_node(self, node): if node is self.tail: self.tail = node.prev else: node.next.prev = node.prev if node is self.head: self.head = node.next else: node.prev.next = node.next self.count -= 1 def get_nodes_data(self): \”\”\”Return list nodes data as a list.\”\”\” data = [] node = self.head while node: data.append(node.data) node = node.next return data |
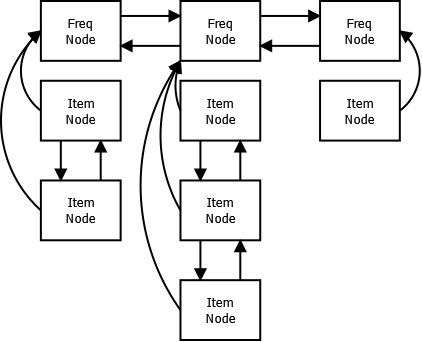
访问频率双向链表中的每个结点都是一个频率结点(下图中的Freq Node)。它是一个结点,同时也是一个包含有相同频率的元素(下图中Item node)的双向性链表。每个条目结点都有一个指向其频率结点父亲的指针。
return node
def insert_item_node(self, data, prev, next):
node = self.insert_node(ItemNode, data, prev, next)
node.parent = self
return node
def remove_item_node(self, node):
self.remove_node(node)
class ItemNode(Node):
def __init__(self, data):
Node.__init__(self, data)
self.parent = None
组。
这篇文章描述了怎么用 Python 实现复杂度为 O(1) 的「最不常用」(Least Frequently Used, LFU)缓存回收算法。在 Ketan Shah、Anirban Mitra 和 Dhruv Matani的论文中有算法描述。实现中的命名是按照论文中的命名。
LFU 缓存回收机制对于 HTTP 缓存网络代理是非常有用的,我们可以从缓存中移除那些最不常使用的条目。
本文旨在设计一个其所有操作的时间复杂度都只有 O(1)的 LFU 缓存算法,这些操作包括了插入、访问和删除(回收)。
这个算法中用了双向链表。其一是用于访问频率,链表中的每个结点都包含一个链表,其中的元素有相同的访问频率。假设缓存中有5个元素。有两个元素被访问了一次,三个元素被访问了两次。在这个例子中,访问频率列表有两个结点(频率为1和2)。第一个频率结点的链表中有两个结点,第二个频率结点的链表中有三个结点。
我们要怎么构建它呢?我们需要的第一个对象是结点:
| 123456 | class Node(object): \”\”\”Node containing data, pointers to previous and next node.\”\”\” def __init__(self, data): self.data = data self.prev = None self.next = None |
接下来是双向链表。每个结点有 prev 和 next 属性,分别等于前一个和下一个结点。head 被设为第一个结点,tail 被设为最后一个结点。
我们可以为双向链表定义方法来在链表尾部加入结点,插入结点,删除结点以及获得链表所有结点的数据。
| 12345678910111213141516171819202122232425262728293031323334353637383940414243444546 | class DoublyLinkedList(object): def __init__(self): self.head = None self.tail = None # Number of nodes in list. self.count = 0 def add_node(self, cls, data): \”\”\”Add node instance of class cls.\”\”\” return self.insert_node(cls, data, self.tail, None) def insert_node(self, cls, data, prev, next): \”\”\”Insert node instance of class cls.\”\”\” node = cls(data) node.prev = prev node.next = next if prev: prev.next = node if next: next.prev = node if not self.head or next is self.head: self.head = node if not self.tail or prev is self.tail: self.tail = node self.count += 1 return node def remove_node(self, node): if node is self.tail: self.tail = node.prev else: node.next.prev = node.prev if node is self.head: self.head = node.next else: node.prev.next = node.next self.count -= 1 def get_nodes_data(self): \”\”\”Return list nodes data as a list.\”\”\” data = [] node = self.head while node: data.append(node.data) node = node.next return data |
访问频率双向链表中的每个结点都是一个频率结点(下图中的Freq Node)。它是一个结点,同时也是一个包含有相同频率的元素(下图中Item node)的双向性链表。每个条目结点都有一个指向其频率结点父亲的指针。