
Python爬虫实战(2):百度贴吧帖子
- Python爬虫入门(1):综述
- Python爬虫入门(2):爬虫基础了解
- Python爬虫入门(3):Urllib库的基本使用
- Python爬虫入门(4):Urllib库的高级用法
- Python爬虫入门(5):URLError异常处理
- Python爬虫入门(6):Cookie的使用
- Python爬虫入门(7):正则表达式
- Python爬虫入门(8):Beautiful Soup的用法
- Python爬虫实战(1):爬取糗事百科段子
- Python爬虫实战(2):百度贴吧帖子
- Python爬虫实战(3):计算大学本学期绩点
- Python爬虫实战(3):计算大学本学期绩点
- Python爬虫实战(5):模拟登录淘宝并获取所有订单
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子。与上一篇不同的是,这次我们需要用到文件的相关操作。
本篇目标
1.对百度贴吧的任意帖子进行抓取
2.指定是否只抓取楼主发帖内容
3.将抓取到的内容分析并保存到文件
1.URL格式的确定
首先,我们先观察一下百度贴吧的任意一个帖子。
比如:http://tieba.baidu.com/p/3138733512?see_lz=1&pn=1,这是一个关于NBA50大的盘点,分析一下这个地址。
| 1234 | http:// 代表资源传输使用http协议 tieba.baidu.com 是百度的二级域名,指向百度贴吧的服务器。 /p/3138733512 是服务器某个资源,即这个帖子的地址定位符 see_lz和pn是该URL的两个参数,分别代表了只看楼主和帖子页码,等于1表示该条件为真 |
所以我们可以把URL分为两部分,一部分为基础部分,一部分为参数部分。
例如,上面的URL我们划分基础部分是 http://tieba.baidu.com/p/3138733512,参数部分是 ?see_lz=1&pn=1
2.页面的抓取
熟悉了URL的格式,那就让我们用urllib2库来试着抓取页面内容吧。上一篇糗事百科我们最后改成了面向对象的编码方式,这次我们直接尝试一下,定义一个类名叫BDTB(百度贴吧),一个初始化方法,一个获取页面的方法。
其中,有些帖子我们想指定给程序是否要只看楼主,所以我们把只看楼主的参数初始化放在类的初始化上,即init方法。另外,获取页面的方法我们需要知道一个参数就是帖子页码,所以这个参数的指定我们放在该方法中。
综上,我们初步构建出基础代码如下:
| 123456789101112131415161718192021222324252627282930 | __author__ = \’CQC\’# -*- coding:utf-8 -*-import urllibimport urllib2import re #百度贴吧爬虫类class BDTB: #初始化,传入基地址,是否只看楼主的参数 def __init__(self,baseUrl,seeLZ): self.baseURL = baseUrl self.seeLZ = \’?see_lz=\’+str(seeLZ) #传入页码,获取该页帖子的代码 def getPage(self,pageNum): try: url = self.baseURL+ self.seeLZ + \’&pn=\’ + str(pageNum) request = urllib2.Request(url) response = urllib2.urlopen(request) print response.read() return response except urllib2.URLError, e: if hasattr(e,\”reason\”): print u\”连接百度贴吧失败,错误原因\”,e.reason return None baseURL = \’http://tieba.baidu.com/p/3138733512\’bdtb = BDTB(baseURL,1)bdtb.getPage(1) |
运行代码,我们可以看到屏幕上打印出了这个帖子第一页楼主发言的所有内容,形式为HTML代码。
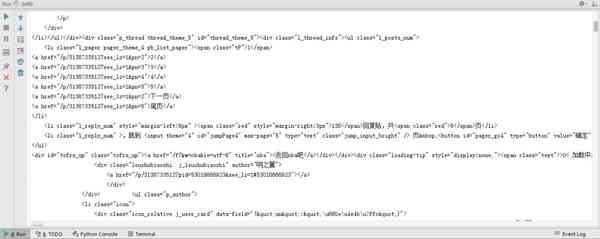
3.提取相关信息
1)提取帖子标题
首先,让我们提取帖子的标题。
在浏览器中审查元素,或者按F12,查看页面源代码,我们找到标题所在的代码段,可以发现这个标题的HTML代码是
| 1 | <h1 title=\”纯原创我心中的NBA2014-2015赛季现役50大\” style=\”width: 396px\”>纯原创我心中的NBA2014–2015赛季现役50大</h1> |
所以我们想提取
标签中的内容,同时还要指定这个class确定唯一,因为h1标签实在太多啦。
正则表达式如下
| 1 | <h1 class=\”core_title_txt.*?>(.*?)</h1> |
所以,我们增加一个获取页面标题的方法
| 12345678910 | #获取帖子标题def getTitle(self): page = self.getPage(1) pattern =/span> self.getPage(1) pattern =ttp://python.jobbole.com/81334/\” target=\”_blank\”>Python爬虫入门(2):爬虫基础了解
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子。与上一篇不同的是,这次我们需要用到文件的相关操作。 本篇目标1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定首先,我们先观察一下百度贴吧的任意一个帖子。 比如:http://tieba.baidu.com/p/3138733512?see_lz=1&pn=1,这是一个关于NBA50大的盘点,分析一下这个地址。
所以我们可以把URL分为两部分,一部分为基础部分,一部分为参数部分。 例如,上面的URL我们划分基础部分是 http://tieba.baidu.com/p/3138733512,参数部分是 ?see_lz=1&pn=1 2.页面的抓取熟悉了URL的格式,那就让我们用urllib2库来试着抓取页面内容吧。上一篇糗事百科我们最后改成了面向对象的编码方式,这次我们直接尝试一下,定义一个类名叫BDTB(百度贴吧),一个初始化方法,一个获取页面的方法。 其中,有些帖子我们想指定给程序是否要只看楼主,所以我们把只看楼主的参数初始化放在类的初始化上,即init方法。另外,获取页面的方法我们需要知道一个参数就是帖子页码,所以这个参数的指定我们放在该方法中。 综上,我们初步构建出基础代码如下:
运行代码,我们可以看到屏幕上打印出了这个帖子第一页楼主发言的所有内容,形式为HTML代码。
3.提取相关信息1)提取帖子标题首先,让我们提取帖子的标题。 在浏览器中审查元素,或者按F12,查看页面源代码,我们找到标题所在的代码段,可以发现这个标题的HTML代码是
所以我们想提取 标签中的内容,同时还要指定这个class确定唯一,因为h1标签实在太多啦。正则表达式如下
所以,我们增加一个获取页面标题的方法
|