
利用 scrapy爬知乎用户关系网以及下载头像
说起Python,我们或许自然而然的想到其在爬虫方面的重大贡献。Python的流行在于其语言的优美以及良好的氛围。相对于Java,js等语言来说,Python API在封装上面要好很多。今天我们要说的是Python的一个通用的开源爬虫框架 scrapy。
scrapy在爬虫界可谓是鼎鼎大名。其内部写好的各种组件使用起来可谓是顺风顺水。各组件的功能我不在此一一列举了,下面教程中会简略提到。整体架构如下图所示:
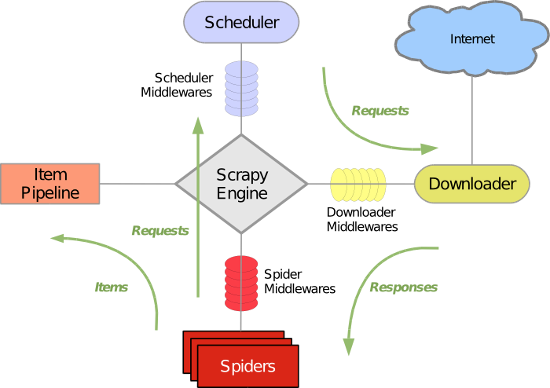

框架简介:
引用自 http://blog.csdn.net/zbyufei/article/details/7554322 已经了解scrapy可以直接略过,也可以当复习使用
一、绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
二、组件
1、Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
2、Scheduler(调度)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
3、Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
4、Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
蜘蛛的整个抓取流程(周期)是这样的:
首先获取第一个URL的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用start_requests()方法。该方法默认从start_urls中的Url中生成请求,并执行解析来调用回调函数。
在回调函数中,你可以解析网页响应并返回项目对象和请求对象或两者的迭代。这些请求也将包含一个回调,然后被Scrapy下载,然后有指定的回调处理。
在回调函数中,你解析网站的内容,同程使用的是Xpath选择器(但是你也可以使用BeautifuSoup, lxml或其他任何你喜欢的程序),并生成解析的数据项。
最后,从蜘蛛返回的项目通常会进驻到项目管道。
5、Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
清洗HTML数据
验证解析到的数据(检查项目是否包含必要的字段)
检查是否是重复数据(如果重复就删除)
将解析到的数据存储到数据库中
6、Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
7、Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
8、Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
三、数据处理流程
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
引擎从调度那获取接下来进行爬取的页面。
调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器。
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
引擎将抓取到的项目项目管道,并向调度发送请求。
系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
模拟登陆
无耻的引用完别人的介绍之后,我们来说说怎样去爬知乎。
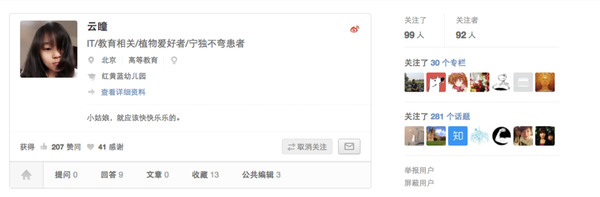
我的思路:通过当前用户的主页拿到其用户数据,如下图:

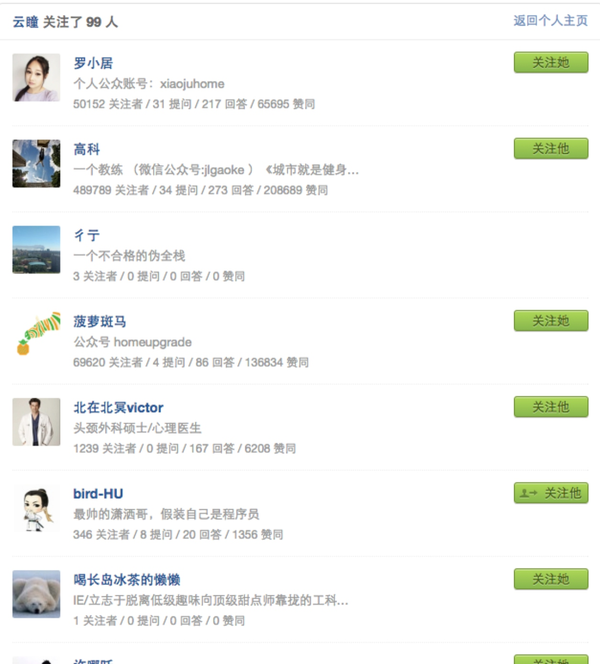
查找其关注的用户和粉丝列表,以其关注者为例:

然后依次取其关注者或者粉丝的数据,最后将爬到的数据进行处理,存入数据库(我这里使用mongodb,mongodb相关知识就不细说了)
如果你尝试过去爬知乎的话,当你爬到起粉丝列表你会发现无论你怎么努力,最后爬到的也只不过是知乎的登录页面:
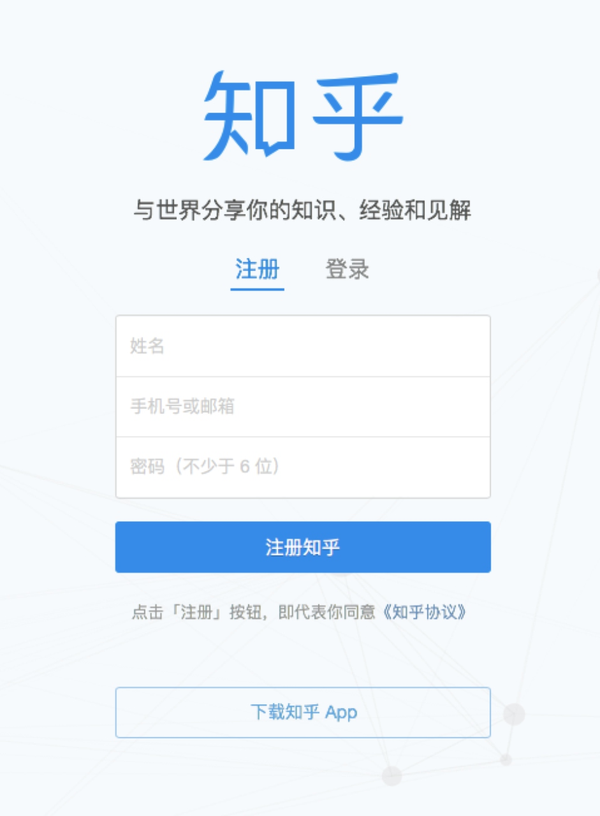

因为知乎是在线用户才能访问其他用户的关注列表和粉丝列表,所以基于此,我们必须伪装在线用户才能拿到数据。
首先我们得知道在线用户在访问知乎的时候向其发送了什么数据。我们在chrome里打开调试器,然后点击network选项卡:
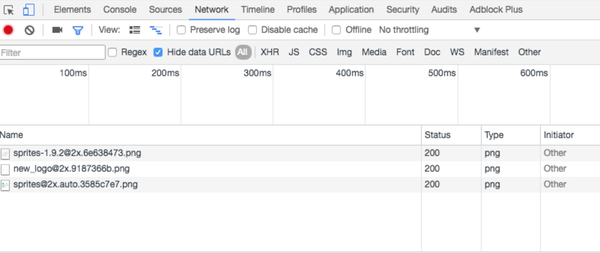

现在几乎是没有什么数据的,此时刷新一下当前页面

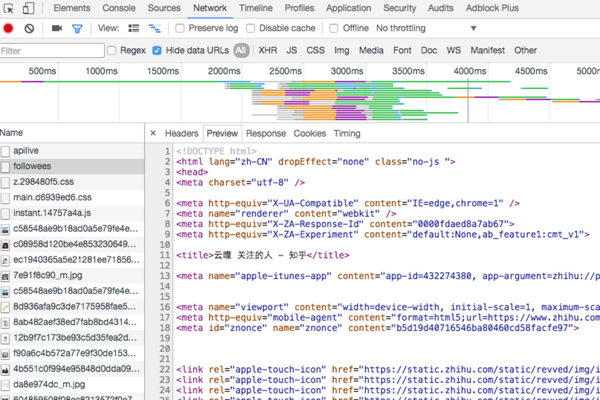
就这样我们看到下载的源码就是已经登录用户的源码了。
代码测试
下面我们要找到发送的参数点击上边的headers选项卡,往下拉倒RequestHeaders,这就是我们要访问知乎所需要的数据:
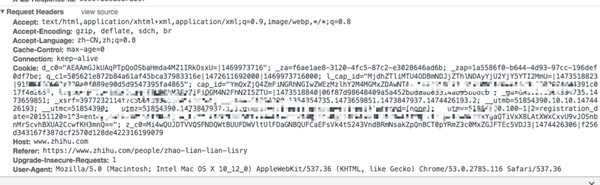

这里主要说一下几个参数:
- User-Agent: 用户代理,主要给服务器提供目前浏览器的参数,不同的用户代理用户获取的数据可能会不一样。服务器也可以根据是否存在此字段来防爬,也可以通过robots.txt来屏蔽掉某些爬虫。
- cookie: 服务器返回的标志用户信息的一些键值对。大多数网站也是基于此验证用户身份的
- Referer:HTTP参照位址,用以表示从哪连接到目前的网页。通过这个字段可以做些图片防盗链处理,这也常被用来对付伪造的跨网站请求。
我们将数据粘贴到接口测试工具里(这里我使用的paw)结果如下:
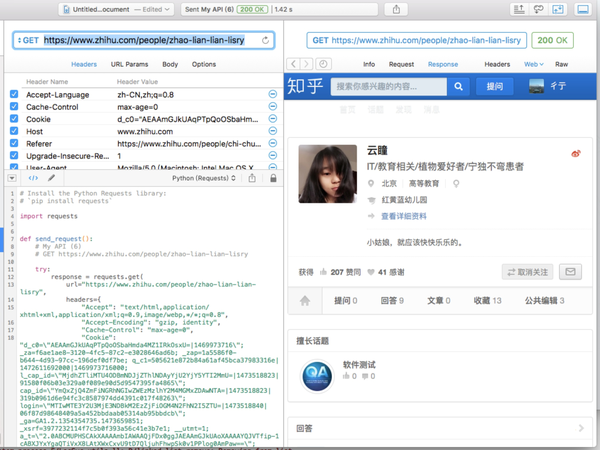

看,我们已经拿到了结果
既然已经拿到了我们想要的数据,那么其粉丝列表自然也就不在话下:

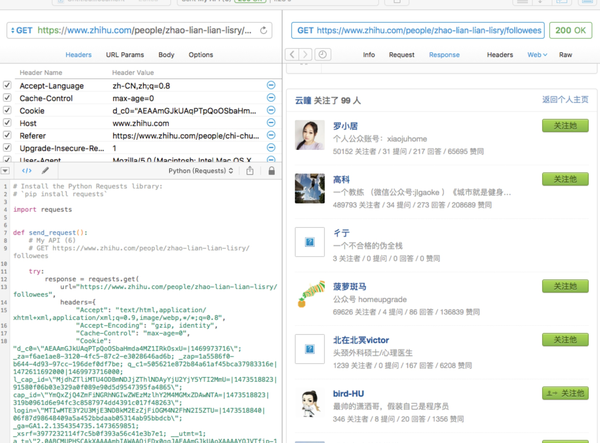
现在我们可以测试下用代码获取数据啦
先利用paw给出的demo来测试下:

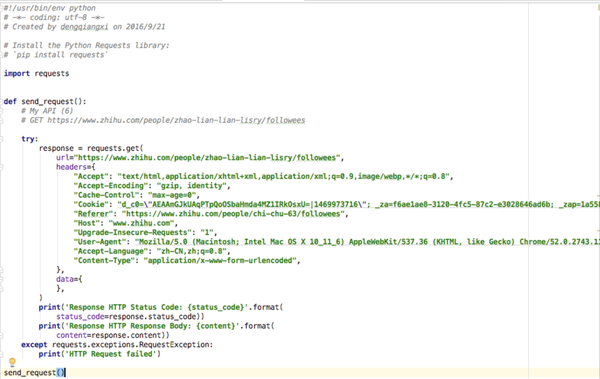
代码如上图所示(这里的代码我就不给出了,没什么东西)

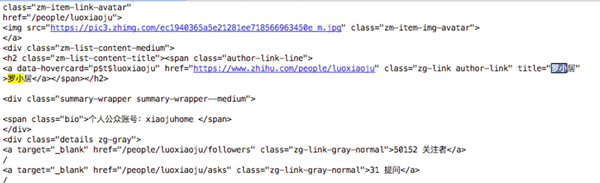
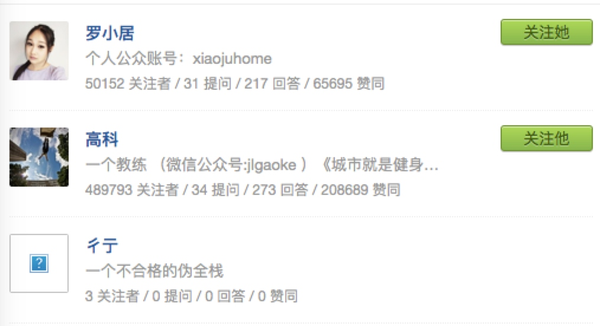

可以证明,我们拿到的数据是对的
当然,这个列表最长只有20个,我会在以后的教程里给出如何获取所有的关注者和粉丝(这里有点小坑)
scrapy上场
好了,万事俱备,就差去爬东西了。
scrapy框架的具体使用方式官方有中文文档,我这里就不详说了
这里直接开始写代码:
设置settings文件
settings文件是爬虫项目的配置文件,我们可以把cookie和header放在这里,用于调用
在这里我做成了两个字典
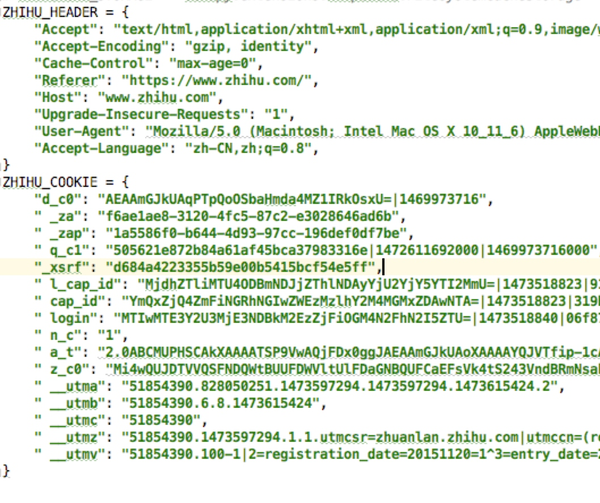
在这里提供一个把一行的cookie分成字典的小工具
print u\'请输入你要分割的 cookie,回车开始分割\'
str = raw_input()
print \'\\n\\n\\n\\n\\n\\n\'
arr = str.split(\';\')
for i in arr:
i = \'\"\' + i
if not i.startswith(\'\"\'):
i = \'\"\' + i
if not i.endswith(\'\"\'):
i += \'\"\'
i += \',\'
arrs = i.split(\'=\', 1)
if not arrs[0].endswith(\'\"\'):
arrs[0] += \'\"\'
if not arrs[1].startswith(\'\"\'):
arrs[1] = \'\"\' + arrs[1]
print \':\'.join(arrs)接下来配置 AutoThrottle,用来设置爬虫的延迟,防止内服务器ban掉ip
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1
AUTOTHROTTLE_MAX_DELAY = 10创建spider文件
在spiders文件夹里创建一个名为ZhihuSpider.py 文件代码如下 :
# -*- coding: utf-8 -*-
from zhihu_spider.settings import *
import scrapy
class ZhihuSpider(scrapy.Spider):
# 爬虫的名字,启动爬虫时需要用
name = \'zhihu\'
# 从哪开始爬
start_urls = [\'https://www.zhihu.com/people/chi-chu-63\']
# 只能爬数组内的域名
allowed_domains = [\'www.zhihu.com\']上面写好了之后,我们需要用上我们设置的COOKIE
这里我们重写下make_requests_from_url方法,把COOKIE传入:
def make_requests_from_url(self, url):
return Request(url, method=\'GET\',headers=ZHIHU_HEADER, cookies=ZHIHU_COOKIE)接下来,在parse方法里通过response参数我们就能通过xpath或者css selector里拿到需要的参数了
# 拿到用户名
response.css(\'.title-section .name::text\').extract_first()配置 item
拿到参数我们需要通过item包装起来,yield出去才能保证数据通过scrapy框架进入下一个流程(处理item)
我们需要写一个类继承 scrapy.Item,代码如下:
class ZhihuSpiderItem(scrapy.Item):
user_name = scrapy.Field() # 用户名
followees = scrapy.Field() # 用户粉丝
followers = scrapy.Field() # 用户关注的人
introduce = scrapy.Field() # 简介
ellipsis = scrapy.Field() # 用户详细介绍
location = scrapy.Field() # 住址
major = scrapy.Field() # 主修
head_image = scrapy.Field() # 头像url
views = scrapy.Field() # 浏览次数
ask = scrapy.Field() # 提问
answer = scrapy.Field() # 回答
articles = scrapy.Field() # 文章
collected = scrapy.Field() # 收藏
public_editor = scrapy.Field() # 公共编辑
main_page = scrapy.Field()
_id = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()接下来,我们在 spider.py文件里将取到的参数放到item里:
def parse(self, response):
item = ZhihuSpiderItem()
user_name = response.css(\'.title-section .name::text\').extract_first()
print user_name
if user_name:
item[\'user_name\'] = user_name
follow = response.css(
\'body > div.zg-wrap.zu-main.clearfix > div.zu-main-sidebar > div.zm-profile-side-following.zg-clear > a> strong::text\').extract()
if follow:
if follow[0]:
item[\'followees\'] = int(follow[0])
if follow[1]:
item[\'followers\'] = int(follow[1])
item[\'introduce\'] = \'\'.join(response.css(
\'div.zg-wrap.zu-main.clearfix > div.zu-main-content > div > div.zm-profile-header.ProfileCard > div.zm-profile-header-main > div > div.zm-profile-header-info > div > div.zm-profile-header-description.editable-group > span.info-wrap.fold-wrap.fold.disable-fold > span.fold-item > span::text\').extract())
item[\'ellipsis\'] = \'\'.join(response.css(
\'body > div.zg-wrap.zu-main.clearfix > div.zu-main-content > div > div.zm-profile-header.ProfileCard > div.zm-profile-header-main > div > div.top > div.title-section > div::text\').extract())
item[\'location\'] = \'\'.join(response.css(\'.location .topic-link::text\').extract())
item[\'major\'] = \'\'.join(response.css(\'.business .topic-link::text\').extract())
head_url = re.sub(r\'_l\\.\', \'.\', \'\'.join(response.css(\'.body .Avatar--l::attr(src)\').extract()))
arr = []
arr.append(head_url)
item[\'head_image\'] = head_url
item[\'image_urls\'] = arr
item[\'ask\'] = int(\'\'.join(response.css(\'.active+ .item .num::text\').extract()))
item[\'answer\'] = int(\'\'.join(response.css(\'.item:nth-child(3) .num::text\').extract()))
item[\'articles\'] = int(\'\'.join(response.css(\'.item:nth-child(4) .num::text\').extract()))
item[\'collected\'] = int(\'\'.join(response.css(\'.item:nth-child(5) .num::text\').extract()))
item[\'public_editor\'] = int(\'\'.join(response.css(\'.item:nth-child(6) .num::text\').extract()))
item[\'views\'] = int(\'\'.join(response.css(\'.zg-gray-normal strong::text\').extract()))
if response.url:
item[\'main_page\'] = response.url
print response.url
item[\'_id\'] = hashlib.sha1(response.url).hexdigest()
yield item这里我使用了 用户url的sha1作为主键_id,用来存入数据库排重
目前我们已经拿到了一个用户的数据,并且yield出去,接下来我们要拿到用户关注的列表:
首先我们先拿到用户关注人数所对应的URL,同样这里用CSS Selector取到URL之后通过一个回调方法进入下一个页面取到关注的用户列表,这里就不赘述了
urls = response.css(
\'body > div.zg-wrap.zu-main.clearfix > div.zu-main-sidebar > div.zm-profile-side-following.zg-clear > a:nth-child(1)::attr(href)\').extract()
if urls:
for url in urls:
url = \'https://www.zhihu.com\' + url
yield scrapy.Request(url=url, callback=self.parse_followers,headers=ZHIHU_HEADER, cookies=ZHIHU_COOKIE)
def parse_followers(self, response):
urls = response.xpath(\'//*[@id=\"zh-profile-follows-list\"]/div/div/a/@href\').extract()
if urls:
for url in urls:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse,headers=ZHIHU_HEADER, cookies=ZHIHU_COOKIE)由此,知乎就可以一直运行下去了。
将item数据存至数据库
处理item主要是由pipeline完成的,在这里我们需要自定义一个pipeline
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from zhihu_spider.items import ZhihuSpiderItem
# from scrapy.contrib.pipeline.images import ImagesPipeline
from scrapy.exceptions import DropItem
class ZhihuSpiderPipeLine(object):
def __init__(self):
import pymongo
connection = pymongo.MongoClient(\'127.0.0.1\', 27017)
self.db = connection[\"zhihu\"]
self.zh_user = self.db[\'zh_user\']
def process_item(self, item, spider):
if isinstance(item, ZhihuSpiderItem):
self.saveOrUpdate(self.zh_user, item)
def saveOrUpdate(self, collection, item):
try:
collection.insert(dict(item))
return item
except:
raise DropItem(\'重复喽\')我们在init方法中初始化了数据库,然后设置相关的 db_name和collection_name
然后将pipeline路径放置到settings.py文件中,scrapy会自动调用
ITEM_PIPELINES = {
\'zhihu_spider.pipelines.ZhihuSpiderPipeLine\': 300,
}下载用户头像
首先将settings.py中的ROBOTSTXT_OBEY设置为False,让爬虫不遵循robots.txt中的规定。不然图片是拿不到的,因为:
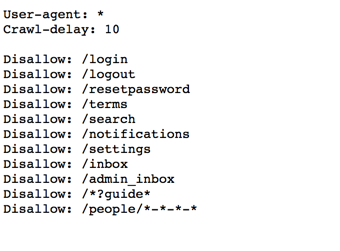
如上图,按照规则,知乎的robots.txt是不允许我们抓取/people/文件夹下的东西的,但是用户头像就是在这。所以不得不卑鄙一回啦~
scrapy已经提供给我们几个写好的的下载器了,我这里使用 默认的ImagePipeline
使用方式很简单,只需要在item里加入
image_urls = scrapy.Field()
images = scrapy.Field()两个字段,然后将头像以数组形式传入image_urls里,然后在settings.py里面添加\'scrapy.contrib.pipeline.images.ImagesPipeline\': 100
到ITEM_PIPELINES字典中便可以了,pipeline路径后边的数字越小,越先被处理,越大越后处理,如果配置有覆盖,数字大的会覆盖小的。
最后一步:设置文件下载路径:将IMAGES_STORE = \'/path/to/image\'添加至settings.py文件中
在命令行中通过 scrapy crawl zhihu 启动爬虫就可以爬取数据了

接下来查询数据库:
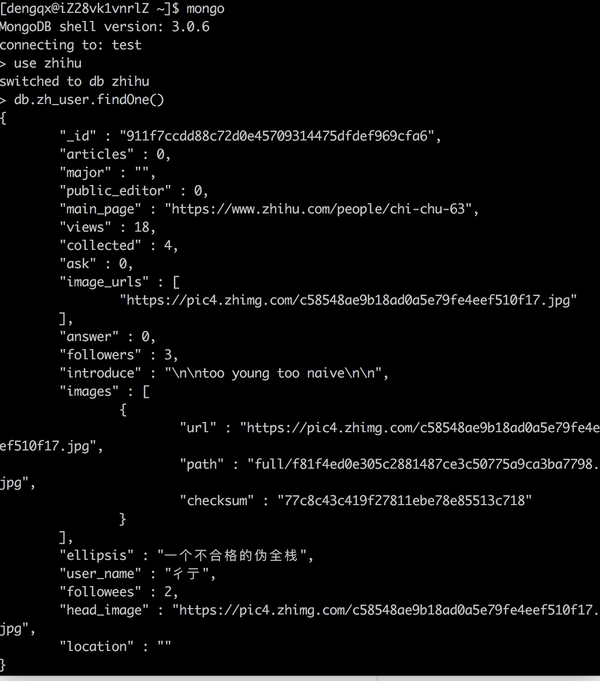
上图就是我的数据了
头像也拿到了
源码地址 https://github.com/dengqiangxi/zhihu_spider.git