
Python爬虫实战(5):模拟登录淘宝并获取所有订单
- Python爬虫入门(1):综述
- Python爬虫入门(2):爬虫基础了解
- Python爬虫入门(3):Urllib库的基本使用
- Python爬虫入门(4):Urllib库的高级用法
- Python爬虫入门(5):URLError异常处理
- Python爬虫入门(6):Cookie的使用
- Python爬虫入门(7):正则表达式
- Python爬虫入门(8):Beautiful Soup的用法
- Python爬虫实战(1):爬取糗事百科段子
- Python爬虫实战(2):百度贴吧帖子
- Python爬虫实战(3):计算大学本学期绩点
- Python爬虫实战(3):计算大学本学期绩点
- Python爬虫实战(5):模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持。
本篇内容
1. python模拟登录淘宝网页
2. 获取登录用户的所有订单详情
3. 学会应对出现验证码的情况
4. 体会一下复杂的模拟登录机制
探索部分成果
1. 淘宝的密码用了AES加密算法,最终将密码转化为256位,在POST时,传输的是256位长度的密码。
2. 淘宝在登录时必须要输入验证码,在经过几次尝试失败后最终获取了验证码图片让用户手动输入来验证。
3. 淘宝另外有复杂且每天在变的 ua 加密算法,在程序中我们需要提前获取某一 ua 码才可进行模拟登录。
4. 在获取最后的登录 st 码时,历经了多次请求和正则表达式提取,且 st 码只可使用一次。
整体思路梳理
1. 手动到浏览器获取 ua 码以及 加密后的密码,只获取一次即可,一劳永逸。
2. 向登录界面发送登录请求,POST 一系列参数,包括 ua 码以及密码等等,获得响应,提取验证码图像。
3. 用户输入手动验证码,重新加入验证码数据再次用 POST 方式发出请求,获得响应,提取 J_Htoken。
4. 利用 J_Htoken 向 alipay 发出请求,获得响应,提取 st 码。
5. 利用 st 码和用户名,重新发出登录请求,获得响应,提取重定向网址,存储 cookie。
6. 利用 cookie 向其他个人页面如订单页面发出请求,获得响应,提取订单详情。
是不是没看懂?没事,下面我将一点点说明自己模拟登录的过程,希望大家可以理解。
前期准备
由于淘宝的 ua 算法和 aes 密码加密算法太复杂了,ua 算法在淘宝每天都是在变化的,不过,这个内容你获取之后一直用即可,经过测试之后没有问题,一劳永逸。
那么 ua 和 aes 密码怎样获取呢?
我们就从浏览器里面直接获取吧,打开浏览器,找到淘宝的登录界面,按 F12 或者浏览器右键审查元素。
在这里我用的是火狐浏览器,首先记得在浏览器中设置一下显示持续日志,要不然页面跳转了你就看不到之前抓取的信息了。在这里截图如下:
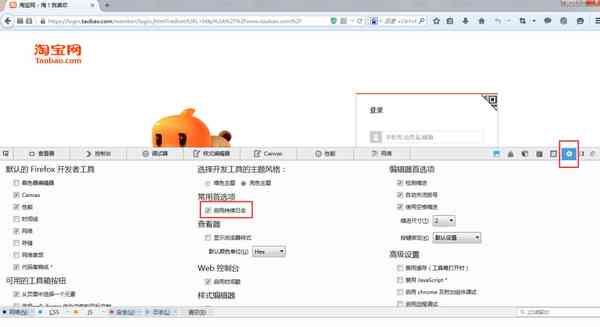
好,那么接下来我们就从浏览器中获取 ua 和 aes 密码
点击网络选项卡,这时都是空的,什么数据也没有截取。这时你就在网页上登录一下试试吧,输入用户名啊,密码啊,有必要时需要输入验证码,点击登录。

等跳转成功后,你就可以看到好多日志记录了,点击图中的那一行 login.taobo.com,然后查看参数,你就会发现表单数据了,其中就包括 ua 还有下面的 password2,把这俩复制下来,我们之后要用到的。这就是我们需要的 ua 还有 aes 加密后的密码。

恩,读到这里,你应该获取到了属于自己的 ua 和 password2 两个内容。
输入验证码并获取J_HToken
经过博主本人亲自验证,有时候,在模拟登录时你并不需要输入验证码,它直接返回的结果就是前面所说的下一步用到的 J_Token,而有时候你则会需要输入验证码,等你手动输入验证码之后,重新请求登录一次。
博主是边写程序边更新文章的,现在写完了是否有必要输入验证码的检验以及在浏览器中呈现验证码。
代码如下
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148 | __author__ = \’CQC\’# -*- coding:utf-8 -*- import urllibimport urllib2import cookielibimport reimport webbrowser #模拟登录淘宝类class Taobao: #初始化方法 def __init__(self): #登录的URL self.loginURL = \”https://login.taobao.com/member/login.jhtml\” #代理IP地址,防止自己的IP被封禁 self.proxyURL = \’http://120.193.146.97:843\’ #登录POST数据时发送的头部信息 self.loginHeaders = { \’Host\’:\’login.taobao.com\’, \’User-Agent\’ : \’Mozilla/5.0 (Windows NT 6.1; WOW64; rv:35.0) Gecko/20100101 Firefox/35.0\’, \’Referer\’ : \’https://login.taobao.com/member/login.jhtml\’, \’Content-Type\’: \’application/x-www-form-urlencoded\’, \’Connection\’ : \’Keep-Alive\’ } #用户名 self.username = \’cqcre\’ #ua字符串,经过淘宝ua算法计算得出,包含了时间戳,浏览器,屏幕分辨率,随机数,鼠标移动,鼠标点击,其实还有键盘输入记录,鼠标移动的记录、点击的记录等等的信息 self.ua = \’191UW5TcyMNYQwiAiwTR3tCf0J/QnhEcUpkMmQ=|Um5Ockt0TXdPc011TXVKdyE=|U2xMHDJ+H2QJZwBxX39Rb1d5WXcrSixAJ1kjDVsN|VGhXd1llXGNaYFhkWmJaYl1gV2pIdUtyTXRKfkN4Qn1FeEF6R31TBQ==|VWldfS0TMw8xDjYWKhAwHiUdOA9wCDEVaxgkATdcNU8iDFoM|VmNDbUMV|V2NDbUMV|WGRYeCgGZhtmH2VScVI2UT5fORtmD2gCawwuRSJHZAFsCWMOdVYyVTpbPR99HWAFYVMpUDUFORshHiQdJR0jAT0JPQc/BDoFPgooFDZtVBR5Fn9VOwt2EWhCOVQ4WSJPJFkHXhgoSDVIMRgnHyFqQ3xEezceIRkmahRqFDZLIkUvRiEDaA9qQ3xEezcZORc5bzk=|WWdHFy0TMw8vEy0UIQE0ADgYJBohGjoAOw4uEiwXLAw2DThu9a==|WmBAED5+KnIbdRh1GXgFQSZbGFdrUm1UblZqVGxQa1ZiTGxQcEp1I3U=|W2NDEz19KXENZwJjHkY7Ui9OJQsre09zSWlXY1oMLBExHzERLxsuE0UT|XGZGFjh4LHQdcx5zH34DRyBdHlFtVGtSaFBsUmpWbVBkSmpXd05zTnMlcw==|XWdHFzl5LXUJYwZnGkI/VitKIQ8vEzKNws3YTc=|XmdaZ0d6WmVFeUB8XGJaYEB4TGxWbk5yTndXa0tyT29Ta0t1QGBeZDI=\’ #密码,在这里不能输入真实密码,淘宝对此密码进行了加密处理,256位,此处为加密后的密码 self.password2 = \’7511aa68sx629e45de220d29174f1066537a73420ef6dbb5b46f202396703a2d56b0312df8769d886e6ca63d587fdbb99ee73927e8c07d9c88cd02182e1a21edc13fb8e140a4a2a4b5c253bf38484bd0e08199e03eb9bf7b365a5c673c03407d812b91394f0d3c7564042e3f2b11d156aeea37ad6460118914125ab8f8ac466f\’ self.post = post = { \’ua\’:self.ua, \’TPL_checkcode\’:\’\’, \’CtrlVersion\’: \’1,0,0,7\’, \’TPL_password\’:\’\’, \’TPL_redirect_url\’:\’http://i.taobao.com/my_taobao.htm?nekot=udm8087E1424147022443\’, \’TPL_username\’:self.username, \’loginsite\’:\’0\’, \’newlogin\’:\’0\’, \’from\’:\’tb\’, \’fc\’:\’default\’, \’style\’:\’default\’, \’css_style\’:\’\’, \’tid\’:\’XOR_1_000000000000000000000000000000_625C4720470A0A050976770A\’, \’support\’:\’000001\’, \’loginType\’:\’4\’, \’minititle\’:\’\’, \’minipara\’:\’\’, \’umto\’:\’NaN\’, \’pstrong\’:\’3\’, \’llnick\’:\’\’, \’sign\’:\’\’, \’need_sign\’:\’\’, \’isIgnore\’:\’\’, \’full_redirect\’:\’\’, \’popid\’:\’\’, \’callback\’:\’\’, \’guf\’:\’\’, \’not_duplite_str\’:\’\’, \’need_user_id\’:\’\’, \’poy\’:\’\’, \’gvfdcname\’:\’10\’, \’gvfdcre\’:\’\’, \’from_encoding \’:\’\’, \’sub\’:\’\’, \’TPL_password_2\’:self.password2, \’loginASR\’:\’1\’, \’loginASRSuc\’:\’1\’, \’allp\’:\’\’, \’oslanguage\’:\’zh-CN\’, \’sr\’:\’1366*768\’, \’osVer\’:\’windows|6.1\’, \’naviVer\’:\’firefox|35\’ } #将POST的数据进行编码转换 self.postData = urllib.urlencode(self.post) #设置代理 self.proxy = urllib2.ProxyHandler({\’http\’:self.proxyURL}) #设置cookie self.cookie = cookielib.LWPCookieJar() #设置cookie处理器 self.cookieHandler = urllib2.HTTPCookieProcessor(self.cookie) #设置登录时用到的opener,它的open方法相当于urllib2.urlopen self.opener = urllib2.build_opener(self.cookieHandler,self.proxy,urllib2.HTTPHandler) #得到是否需要输入验证码,这次请求的相应有时会不同,有时需要验证有时不需要 def needIdenCode(self): #第一次登录获取验证码尝试,构建request request = urllib2.Request(self.loginURL,self.postData,self.loginHeaders) #得到第一次登录尝试的相应 response = self.opener.open(request) #获取其中的内容 content = response.read().decode(\’gbk\’) #获取状态吗 status = response.getcode() #状态码为200,获取成功 if status == 200: print u\”获取请求成功\” #\\u8bf7\\u8f93\\u5165\\u9a8c\\u8bc1\\u7801这六个字是请输入验证码的utf-8编码 pattern = re.compile(u\’\\u8bf7\\u8f93\\u5165\\u9a8c\\u8bc1\\u7801\’,re.S) result = re.search(pattern,content) #如果找到该字符,代表需要输入验证码 if result: print u\”此次安全验证异常,您需要输入验证码\” return content #否则不需要 else: print u\”此次安全验证通过,您这次不需要输入验证码\” return False else: print u\”获取请求失败\” #得到验证码图片 def getIdenCode(self,page): #得到验证码的图片 pattern = re.compile(\' |