
把豆瓣分类电影排行爬回来写进数据库中(完成)
由于最近想做一个爬虫,把爬回来的数据放到数据库中。可是我不懂,MySQL。但由于未来工作很可能都是在Linux上做开发。所以,从前天起我就先掉进了Linux的坑。虚拟机上的centos7先是没有图形界面,原来我用了最小安装。然后重新装了个有图形界面的,结果上不了网。走了一圈百度,折腾了一天还是没解决。到了晚上实在没办法了,有个做运维的群友帮我远程协助解决了。
本以为今天可以开开心心写代码了,结果掉进了MySQL的坑!首先安装mysql,用yum直接install mysql。然后装了个8m的不知道什么东西。结果无法开启mysql服务器,报错找不到好像是sockets这个文件。百度,弄了一个小时都没卵用。最后wget了一个上百兆的回来yum啊什么的各种弄,最后终于成功运行了!!接着百度了个Python教程跟着做。先下载Python~MySQL包,然后开始import以后connect,结果就出问题了。。。又转了半个小时才发现是我没有建立数据库,所以连接不上。那我就退出Python,想先创建database。在命令行输入MySQL,报错!deny!password=no。怎么那么多鸟问题!转一圈百度,十几分钟。换个命令mysql -u root -p 。好了,弹出信息叫我输入密码,输入root。终于成功了!!马上找书,跟着书上演练一遍表的创建与插入。
我以为在mysql,我现在算得上入门了。晚上健身回来,回房间换台电脑用windows开始写代码。结果尼玛密码错误!!!难道密码不是root吗?没办法,继续百度。又瞎弄了一个小时,事情到了无法解决的地步!我把mysql删了,重装!!这次一切正常!明天,我就可以写代码了。。。。。应该吧
好了开始写代码了,然后跳进了代码的坑。由于听说beautifulsoup很好用,我试了一下马上爬了一个table标签的信息。可是当我想进一步提取更多信息的时候。。。。却不知道如何着手。我继续find,select都是给我返回resultset不能find和select的错误。然后string,text,get_text()还一直用不了,报错。之后我放弃了bs,决定用回正则。以前不会正则,现在找了个在线正则匹配的网站后。我一下子学会了正则!幸福感满满的!我也爬到了我想要的信息!
那下一步就是建立数据库吧,意思是我又跳进了数据库的坑!今天是29号,我昨晚弄到两点都没解决的问题:无法插入数据!首先给我报错的是unknown column “ XXX” in the fieldlist,百度一圈没找到解决方法。自己瞎搞胡搞终于解决了这个问题。可是当我要插入数据时又好像出现了编码问题。。。搞定了编码问题,然后 unknow column 又回来了。今天看看能不能解决
昨晚凌晨两点,也就是30号。我终于成功写进了数据库。。。原来我之前是错在了格式化符。。。\'INSERT INTO douban VALUES(null,\"%s\",\"%s\",\"%s\")\'我没有给%s加双引号,就卡了我几个小时
虽然我好不容易把内容写进了数据库。但是,这什么鬼东西?
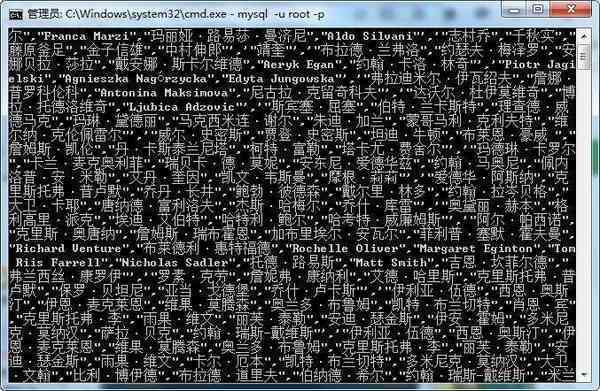
好吧。。。我承认我智商不怎么够,只爬一个页面然后还想把所有内容利用列表嵌套列表的方式分步写进数据库里。。。这思路从一开始就是错的。
一觉睡醒以后,我重新找到了思路。从电影分类页面中找到每一一部电影的链接,爬下来,一个个的打开,再爬取信息,写进数据库。
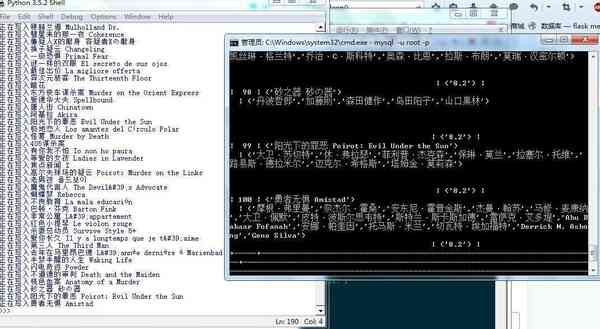
效果图
好了现在可以上代码了
#-*- coding: UTF-8 -*-
from urllib.request import Request, urlopen
from urllib.error import URLError,HTTPError
import re
import sys
import pymysql
import time
import sys
import json
conn = pymysql.connect(host=\"localhost\",user=\"root\",passwd=\"root\",db=\"douban\",charset=\"utf8\")
cur = conn.cursor()
cur.execute(\'DROP TABLE IF EXISTS douban\')
sql = \"\"\"CREATE TABLE douban( id int primary key not null auto_increment,title text,actor text ,rating char(20))\"\"\"
cur.execute(sql)
#连接数据库,查看有没有douban这个表,如果有,删掉然后新建一个
url = \'https://movie.douban.com/j/chart/top_list?type=10&interval_id=100:90&action=&start=20&limit=100\'
req = Request(url)
user_agent = \'Mozilla/5.0 (Windows NT 6.1) AppleWebKit\'
req.add_header(\'User-Agent\' ,user_agent)
try:
response = urlopen(req)
except HTTPError as e:
print (\'The server couldn\\\\\'t fulfill the request.\')
print (\'Error code:\',e.code)
except URLError as e:
print(\'We failed to reach a server.\')
print(\'Reason:\',e.reason)
html = response.read().decode(\'utf-8\')
lp= re.compile(r\'movie.douban.com.*?subject.*?\\\\d+\')
link=lp.findall(html)
#连接豆瓣网,找出分类页面中所有电影的超链接地址
for i in link:
i=(i.replace(\'\\\\\\\\\',\'\'))
#由于找出来的链接都存在着\'\\\\\'这个转义符,所以要替换掉
url =\'https://\'+ i
req = Request(url)
user_agent = \'Mozilla/5.0 (Windows NT 6.1) AppleWebKit\'
req.add_header(\'User-Agent\' ,user_agent)
try:
response = urlopen(req)
except HTTPError as e:
print (\'The server couldn\\\\\'t fulfill the request.\')
print (\'Error code:\',e.code)
except URLError as e:
print(\'We failed to reach a server.\')
print(\'Reason:\',e.reason)
html = response.read().decode(\'utf-8\')
#从找出来的所有链接中,利用for循环一条一条接入
p1 = re.compile(r\'(.*?)\')
p2=re.compile(r\'\"v:starring\">(.*?)\')
p3=re.compile(r\'(.*?)\')
t =p1.findall(html)
a=p2.findall(html)
r=p3.findall(html)
sql2=\'INSERT INTO douban VALUES(null,\"%s\",\"%s\",\"%s\")\'
l=[]
l.append([t,a,r])
cur.executemany(sql2,l)
conn.commit()
for j in t:
print(\"正在写入\"+j)
time.sleep(0.5)
#然后利用正则把每部电影的标题,演员,评分找出来写进数据库
#休息个0.5秒,下一步电影完成以后,我没有休息。今天我又花了一天时间,用同样的思路,爬了一些车牌号。
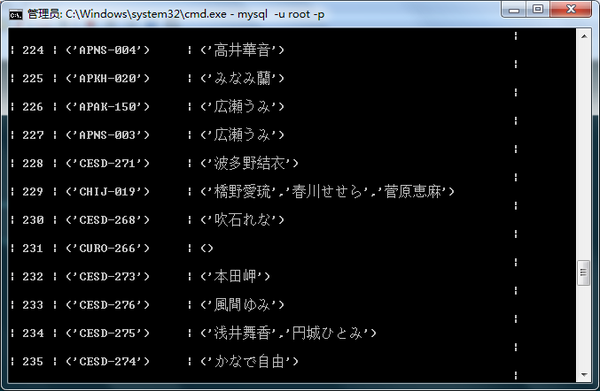
写完以后,我真个人虚脱了,健身房都没力气去。