
Python爬虫实战之爬取糗事百科段子
Python爬虫实战之爬取糗事百科段子
完整代码地址:Python爬虫实战之爬取糗事百科段子
程序代码详解:
-
Spider1-qiushibaike.py:爬取糗事百科的8小时最新页的段子。包含的信息有作者名称,觉得好笑人数,评论人数,发布的内容。如果发布的内容中含有图片的话,则过滤图片,内容依然显示出来。
-
Spider2-qiushibaike.py:在Spider1-qiushibaike.py基础上,引入类和方法,进行优化和封装,爬取糗事百科的24小时热门页的段子。进一步优化,每按一次回车更新一条内容,当前页的内容抓取完毕后,自动抓取下一页的内容,按‘q’退出。
-
Spider3-qiushibaike.py:在Spiders-qiushibaike.py基础上,爬取了百科段子的评论。按C查看当前这个糗事的评论,当切换到查看评论时,换回车显示下一个评论,按Q退出回到查看糗事。糗事段子页数是一页一页加载的,如果你已经看完所有的糗事,就会自动退出!
本爬虫目标:
- 抓取糗事百科热门段子
- 过滤带有图片的段子
- 实现每按一次回车显示一个段子的发布时间,发布人,段子内容,点赞数,评论人数。糗事百科是不需要登录的,所以也没必要用到Cookie,另外糗事百科有的段子是附图的,我们把图抓下来图片不便于显示,那么我们就尝试过滤掉有图的段子吧。好,现在我们尝试抓取一下糗事百科的热门段子吧,每按下一次回车我们显示一个段子。
1.确定URL并抓取页面代码
首先我们确定好页面的URL是 http://www.qiushibaike.com/hot/page/1,其中最后一个数字1代表页数,我们可以传入不同的值来获得某一页的段子内容。
2.提取某一页的所有段子
好,获取了HTML代码之后,我们开始分析怎样获取某一页的所有段子。首先我们审查元素看一下,按浏览器的F12,截图如下:
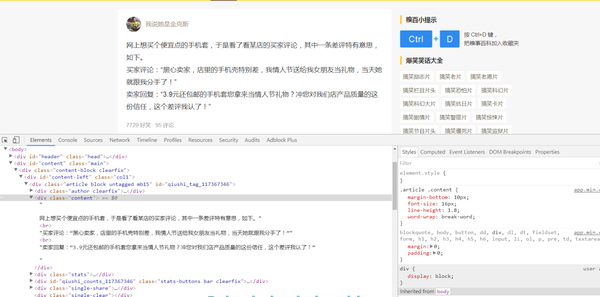
截图
我们可以看到,每一个段子都是
#正则表达式匹配
pattern = re.compile(\'.*?.*?(.*?)
.*?(.*?) 现在正则表达式在这里稍作说明
1).*?是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到.*? 的搭配。
2)(.*?)代表一个分组,在这个正则表达式中我们匹配了五个分组,在后面的遍历item中,item[0]就代表第一个(.*?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。这样我们就获取了发布人,发布时间,发布内容,附加图片以及点赞数。在这里注意一下,我们要获取的内容如果是带有图片,直接输出出来比较繁琐,所以这里我们只获取不带图片的段子就好了。所以,在这里我们就需要对带图片的段子进行过滤。我们可以发现,带有图片的段子会带有类似下面的代码,而不带图片的则没有,所以,我们的正则表达式的item[2]就是获取了下面的内容,如果不带图片,item[2]获取的内容便是空,所以我们只需要判断item[2]中是否含有img标签就可以了。
整体代码如下:
#-*-coding:utf8-*-
#created by 10412 2016/8/23
#爬取糗事百科的8小时最新页的段子。包含的信息有作者名称,觉得好笑人数,评论人数,发布的内容。
#如果发布的内容中含有图片的话,则过滤图片,内容依然显示出来。
import urllib
import urllib2
import re
#自定义输入爬取的页数
page = raw_input(\"please enter the page number:\")
url = \'http://www.qiushibaike.com/8hr/page/\'+ page +\'/?s=4880477
\'user_agent = \'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)\'headers = { \'User-Agent\' : user_agent }
try:
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
content = response.read().decode(\'utf-8\')
#正则表达式匹配
pattern = re.compile(\'.*?.*?(.*?)
.*?(.*?) 运行一下看下效果:
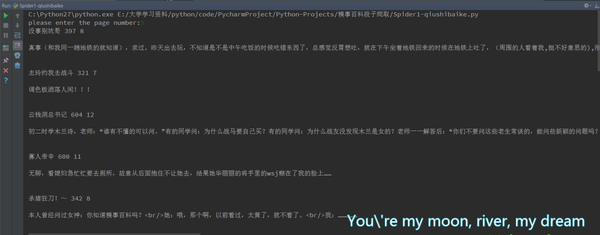
运行截图
恩,带有图片的段子已经被剔除啦。
3.完善交互,设计面向对象模式
好啦,现在最核心的部分我们已经完成啦,剩下的就是修一下边边角角的东西,我们想达到的目的是:按下回车,读取一个段子,显示出段子的发布人,内容,点赞个数及评论数量。另外我们需要设计面向对象模式,引入类和方法,将代码做一下优化和封装,最后,我们的代码如下所示
#-*-coding:utf8-*-
#created by 10412
# 在Spider1-qiushibaike.py基础上,引入类和方法,进行优化和封装,爬取糗事百科的24小时热门页的段子。
# 进一步优化,每按一次回车更新一条内容,当前页的内容抓取完毕后,自动抓取下一页的内容,按‘q’退出。
import urllib2
import re
class QSBK:
def __init__(self): self.pageIndex = 1 self.user_agent = \'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)\' self.headers = {\'User-Agent\' : self.user_agent} self.stories = [] # 存放程序是否继续运行的变量 self.enable = False # 传入某一页的索引获得页面代码 def getPage(self, pageIndex): try: url = \'http://www.qiushibaike.com/hot/page/\' + str(pageIndex) request = urllib2.Request(url, headers=self.headers) response = urllib2.urlopen(request) pageCode = response.read().decode(\'utf-8\') return pageCode except urllib2.URLError, e: if hasattr(e, \"reason\"): print u\"连接糗事百科失败,错误原因\", e.reason return None # 传入某一页代码,返回本页不带图片的段子列表 def getPageItems(self, pageIndex): pageCode = self.getPage(pageIndex) if not pageCode: print u\"出错了\" return None pattern = re.compile(\'\' pattern = re.compile(pattrenStr, re.S) items = re.findall(pattern, pageContent) return items def getCurrentStoryComments(self, storyId): #切换到查看评论模式 self.viewComment = True content = self.getCommentsContent(storyId) if not content: print \"页面加载失败...\" return None reStr = r\'.*?)\">(?P=username).*?\'\\ r\'(?P.*?) .*?\'\\ r\'(?P.*?) \' pattern = re.compile(reStr, re.S) items = re.findall(pattern, content) del self.comments[:] for item in items: comentstr = item[0]+\'(\'+ item[2] + u\'楼)\' + \'\\n\' + item[1] + \'\\n\' for (k,v) in htmlCharacterMap.items(): re.sub(re.compile(k), v, comentstr) self.comments.append(comentstr) if len(self.comments)>0: print \'已切换到查看评论,换回车显示下一个评论,按Q退出回到查看糗事\' else: print \'当前糗事没有评论\' self.viewComment = False def getNextPage(self): if self.pageIndex > self.pagetotal: self.enable = False print \"你已经看完所有的糗事,现在自动退出!\" return items = self.getPageItems(self.pageIndex) self.pageIndex += 1 for item in items: #如果有图片直接跳过,因为图片在终端显示不了 if re.search(\'img\', item[2]): continue content = item[1].strip() #转换html的特殊字符 for (k,v) in htmlCharacterMap.items(): content = re.sub(re.compile(k), v, content) authorname = item[0].strip() for (k,v) in htmlCharacterMap.items(): authorname = re.sub(re.compile(k), v, authorname) #找出评论个数,没有为0 pattern = re.compile(r\'.*?.*?)\".*?(?P.*?) .*?\', re.S) result = re.match(pattern, item[4]) commentnumbers = 0 articleId = \'\' if result: commentnumbers = result.groupdict().get(\'number\', \'0\') articleId = result.groupdict().get(\'id\', \'\') self.stories.append(authorname + \'(\' + item[3].strip() + u\'好笑·\' + str(commentnumbers) + u\'评论)\' + \'\\n\' + content + \'\\n\') self.stories.append(articleId) def getNextComment(self): print self.comments[0] self.comments.pop(0) if len(self.comments)==0: print \'你已查看完这个糗事的所有评论,现在自动退出到查看糗事\' self.viewComment = False def getOneStory(self): #防止有的页面全是带图片的 while (len(self.stories)==0 and self.enable): self.getNextPage() story = self.stories[0] self.currentStoryId = self.stories[1] print story self.stories.pop(0) self.stories.pop(0) if len(self.stories)==0: self.getNextPage() def start(self): #先删除临时保存的网页 tempfiles = [x for x in os.listdir(\'.\') if os.path.isfile(x) and os.path.splitext(x)[1]==\'.html\' and x.startswith(\'temp\')] for file in tempfiles: os.remove(file) print u\"正在读取糗事百科,按回车查看下一个糗事,按C查看当前这个糗事的评论,按Q退出或返回\" self.enable = True self.getNextPage() while self.enable: input = raw_input() if input.upper() == \"Q\": if not self.viewComment: self.enable = False else: self.viewComment = False print \'现在退出到查看糗事了\' elif input.upper() == \"C\": #查看当前看到的糗事的评论 if len(self.currentStoryId)>0: self.getCurrentStoryComments(self.currentStoryId) else: print \'这条糗事没有评论\' else: if not self.viewComment: self.getOneStory() else: self.getNextComment()if __name__ == \'__main__\': spider = QSBK() spider.start()
相关内容