
小作品: Python 命令行词典(附源码)
admin
2023-07-30 21:21:52
0次
python-translate
python-translate 是一个简单的命令行翻译工具,数据源自必应、有道及爱词霸翻译服务。
GitHub 仓库 https://github.com/caspartse/python-translate
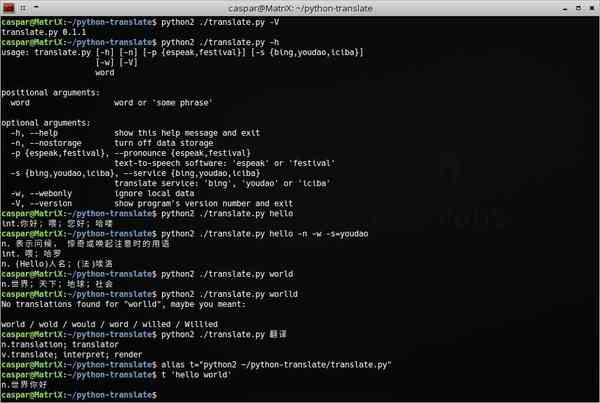
代码说明
- Python 版本
python 2.6 + - 演示环境
BunsenLabs Linux Hydrogen (Debian GNU/Linux 8.5)
基本功能
- 英汉 / 汉英 翻译
- 拼写检查及拼写建议(仅英文)
- 数据存储 (使用 dbm 模块)
- 单词发音
使用方法
usage: translate.py [-h] [-n] [-p {espeak,festival}] [-s {bing,youdao,iciba}]
[-w] [-V]
word
positional arguments:
word word or \'some phrase\'
optional arguments:
-h, --help show this help message and exit
-n, --nostorage turn off data storage
-p {espeak,festival}, --pronounce {espeak,festival}
text-to-speech software: \'espeak\' or \'festival\'
-s {bing,youdao,iciba}, --service {bing,youdao,iciba}
translate service: \'bing\', \'youdao\' or \'iciba\'
-w, --webonly ignore local data
-V, --version show program\'s version number and exit-
关于查询结果保存
默认保存查询结果,如需关闭,可使用-n或--nostorage选项。$ python2 translate.py hello -n -
关于本地数据使用
默认使用本地数据库,如需关闭,可使用-w或--webonly选项。$ python2 translate.py hello -w -
关于翻译服务选择
可使用-s或--service选项指定翻译服务:bing | youdao | iciba ,默认使用必应翻译。以下三种表示方法均有效:$ python2 translate.py hello -s=youdao $ python2 translate.py hello -s youdao $ python2 translate.py hello -syoudao -
关于单词发音
单词发音功能默认关闭,如需启用,可使用-p或--pronounce选项,选择具体的软件发音: espeak | festival 。
可修改源码中的pronounce部分以更改 eSpeak 或 Festival 的发音配置。
另外 TTS 合成语音效果一般,若有真人语音文件,可配合 aplay、mpg321、sox 等命令使用。
p.s. 语音资源可搜索 \”OtdRealPeopleTTS\”、\”WyabdcRealPeopleTTS\” 等关键词。$ python2 translate.py hello -p=espeak $ python2 translate.py hello -p=festival
库依赖 & 软件支持
- requests
- Beautiful Soup 4
- lxml
- pyenchant
$ pip install requests beautifulsoup4 lxml pyenchant
# OR
$ pip install -r requirements.txt- eSpeak (发音需要,可选择安装)
- Festival (发音需要,可选择安装)
$ sudo apt-get install espeak festival小贴士
- 设置命令别名
$ alias t=\"python2 /path/to/the/translate.py\" $ alias te=\"t -p=espeak\" $ alias tf=\"t -p=festival\" - data 文件夹内包含了 10000 个高频单词的英文翻译结果
- 修改 hosts 配置可加速在线查询,参考 utils 文件夹中的 hosts 文件
- 预先批量查询单词并保存结果,可作离线词典使用
更多资源
- SCOWL (Spell Checker Oriented Word Lists)
- List of spell checkers
- Wiktionary:Frequency lists
- wordlist.10000
- top10000en.txt
- google-10000-english
源码(v0.1.1)
#!/usr/bin/env python
# -*- coding:utf-8 -*
import os
import argparse
import dbm
import re
from multiprocessing.dummy import Pool as ThreadPool
from multiprocessing import Process
class Bing(object):
def __init__(self):
super(Bing, self).__init__()
def query(self, word):
import requests
from bs4 import BeautifulSoup
sess = requests.Session()
headers = {
\'Host\': \'cn.bing.com\',
\'User-Agent\': \'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0\',
\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\',
\'Accept-Language\': \'en-US,en;q=0.5\',
\'Accept-Encoding\': \'gzip, deflate\',
}
sess.headers.update(headers)
url = \'http://cn.bing.com/dict/SerpHoverTrans?q=%s\' % (word)
try:
resp = sess.get(url, timeout=30)
except:
return None
text = resp.text
if (resp.status_code == 200) and (text):
soup = BeautifulSoup(text, \'lxml\')
if soup.find(\'h4\').text.strip() != word.decode(\'utf-8\'):
return None
lis = soup.find_all(\'li\')
trans = []
for item in lis:
transText = item.get_text()
if transText:
trans.append(transText)
return \'\\n\'.join(trans)
else:
return None
class Youdao(object):
def __init__(self):
super(Youdao, self).__init__()
def query(self, word):
import requests
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
sess = requests.Session()
headers = {
\'Host\': \'dict.youdao.com\',
\'User-Agent\': \'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0\',
\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\',
\'Accept-Language\': \'en-US,en;q=0.5\',
\'Accept-Encoding\': \'gzip, deflate\'
}
sess.headers.update(headers)
url = \'http://dict.youdao.com/fsearch?q=%s\' % (word)
try:
resp = sess.get(url, timeout=30)
except:
return None
text = resp.content
if (resp.status_code == 200) and (text):
tree = ET.ElementTree(ET.fromstring(text))
returnPhrase = tree.find(\'return-phrase\')
if returnPhrase.text.strip() != word.decode(\'utf-8\'):
return None
customTranslation = tree.find(\'custom-translation\')
if not customTranslation:
return None
trans = []
for t in customTranslation.findall(\'translation\'):
transText = t[0].text
if transText:
trans.append(transText)
return \'\\n\'.join(trans)
else:
return None
class Iciba(object):
def __init__(self):
super(Iciba, self).__init__()
def query(self, word):
import requests
from bs4 import BeautifulSoup
sess = requests.Session()
headers = {
\'Host\': \'open.iciba.com\',
\'User-Agent\': \'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0\',
\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\',
\'Accept-Language\': \'en-US,en;q=0.5\',
\'Accept-Encoding\': \'gzip, deflate\'
}
sess.headers.update(headers)
url = \'http://open.iciba.com/huaci_new/dict.php?word=%s\' % (word)
try:
resp = sess.get(url, timeout=30)
text = resp.text
pattern = r\'([\\s\\S]+?)\'
text = re.search(pattern, text).group(1)
except:
return None
if (resp.status_code == 200) and (text):
soup = BeautifulSoup(text, \'lxml\')
ps = soup.find_all(\'p\')
trans = []
for item in ps:
transText = item.get_text()
transText = re.sub(
r\'\\s+\', \' \', transText.replace(\'\\t\', \'\')).strip()
if transText:
trans.append(transText)
return \'\\n\'.join(trans)
else:
return None
path = os.path.dirname(os.path.realpath(__file__))
db = dbm.open(path + \'/data/vocabulary\', \'c\')
class Client(object):
def __init__(self, word, service=\'bing\', webonly=False):
super(Client, self).__init__()
self.service = service
self.word = word
self.trans = None
if webonly:
self.db = {}
else:
self.db = db
def translate(self):
trans = self.db.get(self.word)
if trans:
return trans
else:
if self.service == \'bing\':
S = Bing()
if self.service == \'youdao\':
S = Youdao()
elif self.service == \'iciba\':
S = Iciba()
trans = S.query(self.word)
self.trans = trans
return trans
def suggest(self):
if re.sub(r\'[a-zA-Z\\d\\\'\\-\\.\\s]\', \'\', self.word):
return None
import enchant
try:
d = enchant.DictWithPWL(
\'en_US\', path + \'/data/spell-checker/american-english\')
except:
d = enchant.Dict(\'en_US\')
suggestion = d.suggest(self.word)
return suggestion
def pronounce(self, tts):
if tts == \'festival\':
cmd = \' echo \"%s\" | festival --tts > /dev/null 2>&1\' % (self.word)
elif tts == \'espeak\':
cmd = \'espeak -v en-us \"%s\" > /dev/null 2>&1\' % (self.word)
import commands
try:
status, output = commands.getstatusoutput(cmd)
except:
pass
return True
def updateDB(self):
if self.trans:
db[self.word] = self.trans.encode(\'utf-8\')
db.close()
return True
def parseArgs():
parser = argparse.ArgumentParser()
parser.add_argument(\'word\', help=\"word or \'some phrase\'\")
parser.add_argument(\'-n\', \'--nostorage\', dest=\'nostorage\',
action=\'store_true\', help=\'turn off data storage\')
parser.add_argument(\'-p\', \'--pronounce\', dest=\'pronounce\', choices=[
\'espeak\', \'festival\'], help=\"text-to-speech software: \'espeak\' or \'festival\'\")
parser.add_argument(\'-s\', \'--service\', dest=\'service\', choices=[
\'bing\', \'youdao\', \'iciba\'], default=\'bing\', help=\"translate service: \'bing\', \'youdao\' or \'iciba\'\")
parser.add_argument(\'-w\', \'--webonly\', dest=\'webonly\',
action=\'store_true\', help=\'ignore local data\')
parser.add_argument(\'-V\', \'--version\', action=\'version\',
version=\'%(prog)s 0.1.1\')
return parser.parse_args()
if __name__ == \'__main__\':
args = parseArgs()
word = args.word.strip()
service = args.service
webonly = args.webonly
C = Client(word, service=service, webonly=webonly)
pool = ThreadPool()
_trans = pool.apply_async(C.translate)
_suggestion = pool.apply_async(C.suggest)
trans = _trans.get()
if trans:
print trans
if args.pronounce:
p1 = Process(target=C.pronounce, args=(args.pronounce,))
p1.daemon = True
p1.start()
if not args.nostorage:
p2 = Process(target=C.updateDB)
p2.daemon = True
p2.start()
else:
suggestion = _suggestion.get()
if not suggestion:
print \'No translations found for \\\"%s\\\" .\' % (word)
else:
print \'No translations found for \\\"%s\\\", maybe you meant:\\
\\n\\n%s\' % (word, \' / \'.join(suggestion))欢迎 Star / Fork: https://github.com/caspartse/python-translate (^-^*)
上一篇:Django学习笔记
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...