
9.Python3爬虫实例——使用Scrapy重构代码爬取名著
admin
2023-07-30 21:11:41
0次
1.准备
- 安装:pip install scrapy==1.1.0rc3
- 参考资料:官方1.0文档
2.使用Scrapy重构代码
2.1创建新项目
- 使用cmd进入待建项目的文件夹中,输入:
scrapy startproject 项目名项目就建好了,项目结构图如下:
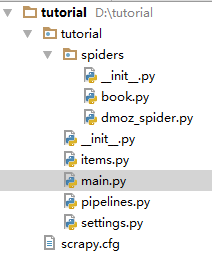
- spiders文件夹是存放各种爬虫的文件夹
items是存储爬取对象的属性定义的文件
settings是Scrapy设置的文件
2.2 定义要爬取的对象的属性
- 在items.py中添加:
class BookName(Item): name=Field() url=Field() class BookContent(Item): id=Field() title=Field() text=Field()
2.3 定义爬虫
-
在Spider文件夹内添加文件book.py。并书写代码如下:
class BookSpider(CrawlSpider): name=\"book\"#爬虫名字 allowed_domains=[\"shicimingju.com\"]#允许的域名 start_urls=[#开始爬取的网站 \"http://www.shicimingju.com/book/sanguoyanyi.html\" ] -
我直接是使用的CrawlSpider,一个更加方便定义爬取连接规则的类型。
allow对应爬取的网站,使用了正则,callback对应对于该网站使用的方法。rules=( Rule(LinkExtractor(allow=(\'http://www.shicimingju.com/book/sanguoyanyi.html\',)),callback=\'bookMenu_item\'), Rule(LinkExtractor(allow=\"http://www.shicimingju.com/book/.*?\\d*?\\.html\"),callback=\"bookContent_item\") ) - 读取书的名字
def bookMenu_item(self,response): sel=Selector(response) bookName_items=[] bookName_item=BookName() bookName_item[\'name\']=sel.xpath(\'//*[@id=\"bookinfo\"]/h1/text()\').extract() print(bookName_item) bookName_items.append(bookName_item) return bookName_items - 读取每章内容并保存id顺序,因为Scrapy是异步的,所以需要保存章节顺序。
def bookContent_item(self,response): global num print(num) num+=1 sel = Selector(response) bookContent_items = [] bookContent_item = BookContent() bookContent_item[\'id\']=re.findall(\'.*?(\\d+).*?\',response.url) bookContent_item[\'title\']=sel.xpath(\'//*[@id=\"con\"]/h2/text()\').extract() bookContent_item[\'text\']=\"\".join(sel.xpath(\'//*[@id=\"con2\"]/p/descendant::text()\').extract()) bookContent_item[\'text\']=re.sub(\'\\xa0\',\' \',bookContent_item.get(\'text\')) print(bookContent_item) bookContent_items.append(bookContent_item) return bookContent_items
2.4 执行爬虫
- 普通的执行方法,在cmd中输入:
scrapy crawl book - 在pycharm中的执行方法 stackoverflow
3.总结
- 可能会出现的问题:
- ImportError : cannot import name \’_win32stdio\’ 解决方法
- python3 使用scrapy的crawlspider问题 解决方法:查看最新的官方文档。
- xpath: 所有\”< p >\”标签下的内容:xpath(\’//p/descendant::text()\’)
只需要< p >或者< strong >下内容:xpath(\’//p/text()|//p/strong/text()\’)
xpath也是个大坑,改天把它填了。
上一篇:Django学习笔记
下一篇:Django学习笔记
相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...