
爬虫基础知识
admin
2023-07-30 21:05:25
0次
URL介绍

URL介绍.png
请求介绍
如何通过urllib2实现请求,参看下图:

通过urllib2完成请求.png
使用 HTTP 的 PUT 和 DELETE 方法
import urllib2
request = urllib2.Request(uri, data=data)
request.get_method = lambda: \'PUT\' # or \'DELETE\'
response = urllib2.urlopen(request)异常处理
from urllib2 import Request, urlopen, URLError, HTTPError
req = Request(\'http://www.jianshu.com/users/92a1227beb27/latest_articles\')
try:
response = urlopen(req)
except URLError, e:
if hasattr(e, \'code\'):
print \'The server couldn\'t fulfill the request.\'
print \'Error code: \', e.code
elif hasattr(e, \'reason\'):
print \'We failed to reach a server.\'
print \'Reason: \', e.reason数据解析
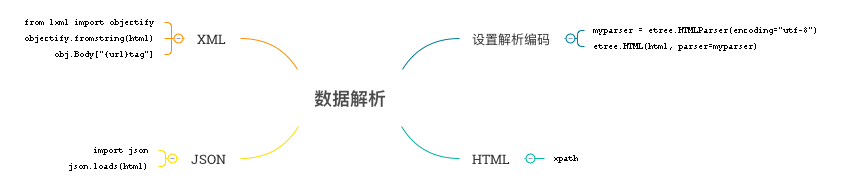
数据解析.png
写出的测试示例
# coding:utf-8
import urllib2
from lxml import etree
import sys
print sys.getdefaultencoding()
reload(sys)
sys.setdefaultencoding(\'utf-8\')
#网站数据复杂,暂时还没有处理方法
def oper(url):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6\'
}
req = urllib2.Request(url=url,headers=headers)
try:
response = urllib2.urlopen(req)
except urllib2.URLError,e:
print e.reason
html = response.read()
myparser = etree.HTMLParser(encoding=\"utf-8\")
selector = etree.HTML(html, parser=myparser)
stainfos = selector.xpath(\'//input[@name=\"stainfo\"]/@value\')
for stainfo in stainfos:
print stainfo
stanames = selector.xpath(\'//input[@name=\"staname\"]/@value\')
for staname in stanames:
print staname
stainfodbys = selector.xpath(\'//input[@name=\"stainfodby\"]/@value\')
for stainfodby in stainfodbys:
print stainfodby
def start():
urls = [\'http://58.68.130.147/#\']
for url in urls:
oper(url)
if __name__ == \'__main__\':
start()相关内容
热门资讯
500 行 Python 代码...
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们...
定时清理删除C:\Progra...
C:\Program Files (x86)下面很多scoped_dir开头的文件夹 写个批处理 定...
65536是2的几次方 计算2...
65536是2的16次方:65536=2⁶
65536是256的2次方:65536=256
6553...
Mobi、epub格式电子书如...
在wps里全局设置里有一个文件关联,打开,勾选电子书文件选项就可以了。
scoped_dir32_70...
一台虚拟机C盘总是莫名奇妙的空间用完,导致很多软件没法再运行。经过仔细检查发现是C:\Program...
pycparser 是一个用...
`pycparser` 是一个用 Python 编写的 C 语言解析器。它可以用来解析 C 代码并构...
python绘图库Matplo...
本文简单介绍了Python绘图库Matplotlib的安装,简介如下:
matplotlib是pyt...
Prometheus+Graf...
一,Prometheus概述
1,什么是Prometheus?Prometheus是最初在Sound...
小程序支付时提示:appid和...
[Q]小程序支付时提示:appid和mch_id不匹配
[A]小程序和微信支付没有进行关联,访问“小...
微信小程序使用slider实现...
众所周知哈,微信小程序里面的音频播放是没有进度条的,但最近有个项目呢,客户要求音频要有进度条控制,所...