
爬取简书全站文章并生成 API(一)

简书
简书中的优质文章非常多,而且我非常喜欢 Markdown 这种语法格式,所以想着能不能爬取简书上面的文章,爬取文章之前先带大家来了解下简书整个网站,简书的首页分为“热门(已推到首页的)“,“新上榜(编辑已通过,但还没上首页的文章,等待队列中)”,“日报”,“七日热门”和“三十日热门”,“有奖活动”,“简书出版”和“简书播客”。简书还有一种绕开等待队列上首页的方式,就是“今日看点”专题,这个是不能投稿,编辑快速把文章推到首页的方式。
下面带大家爬取的是简书的 “热门” 和 “新上榜” 这两个目录里面的文章,“热门”每页有 20 篇文章,最多可以加载 15 页。“新上榜” 每页有 18 篇文章,可以加载的页数没有限制,理论可以爬取所有的文章。
-
爬取简书全站文章并生成 API(二)
-
爬取简书全站文章并生成 API(三)
-
爬取简书全站文章并生成 API(四)
-
爬取简书全站文章并生成 API(五)
-
简书 API 测试地址 : http://222.24.63.118:8080/
-
github 项目地址:https://github.com/strugglingyouth/jianshu/
1. 网页源码分析:
以下是简书首页文章处的源码:
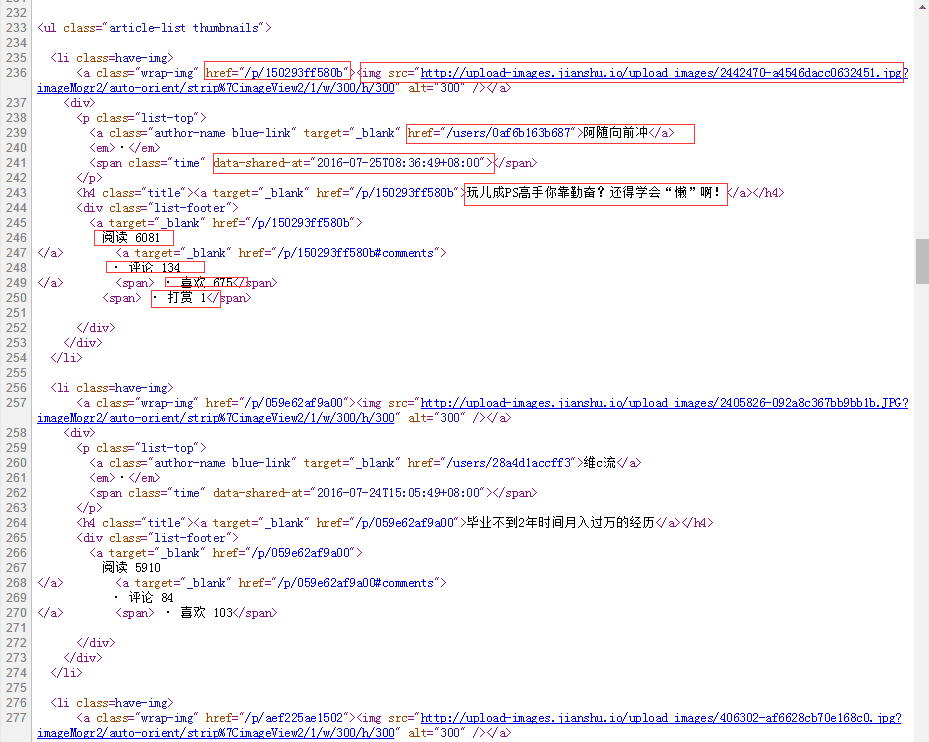
文章源码
若文章没有被打赏过,则“打赏”在网页源码中不会存在,代码中会进行处理,剩下的都会存在,但在爬取“热门”目录下的文章时,“阅读数”,“评论数”,“喜欢” 也会出问题,所以代码中也都做了相应的处理。

data-url
data-url 对应下一页的 URL。
简书各个目录代码格式相同,所以相同的方法也可以爬取简书其余几个分类目录。
2. 爬取简书热门文章
此爬虫使用 python 的 BeautifulSoup 模块进行爬取,BeautifulSoup 模块的使用方法可以参照 BeautifulSoup 模块使用指南。
“热门” 目录每页有 20 篇文章,底部有一个 “点击查看更多” 的按钮,此按钮对应一个 data-url 用于加载下一页的文章。爬取当前页面的所有文章后,提取页面底部的 data-url ,再爬取对应 URL 页面的文章,依此步骤递归爬取,可以获得 “热门” 目录中的所有文章。爬取到文章的信息有“文章ID”,“文章标题”,“文章URL”,“作者”,“作者的URL”,“缩略图URL”,“文章内容”,“发表时间”,“阅读数”,“评论数”,“喜欢”,“打赏”,“热门”目录每一小时爬取一次。
代码中使用 Django orm 来生成所需要的数据库,若不熟悉 Django,请参阅官方文档 Django 官方文档 或者对应的 中文翻译文档。数据库设计代码参考 jianshu 目录下 models.py 文件,爬虫代码参考 popular_articles_jianshu.py 文件。
3. 爬取简书新上榜的文章
对于新上榜中的内容,每次只爬取当前页面中的所有文章,15 分钟爬取一次,不会递归爬取所有页,API 分为文章概要和文章详细信息,文章概要包含“文章ID”,“文章标题”,“文章URL”,“作者”和“作者的URL”,文章详细信息包括“缩略图URL”,“文章标题”,“文章内容”,“发表时间”,“阅读数”,“评论数”,“喜欢”,“打赏”,API 每次返回 18 篇文章的信息。
4. 爬取搜索到的文章
本来想爬取简书中某一类技术文章,由于简书没有明显的分类目录,文章也没有对应的 tag 所以准备爬取搜索到的文章。
下面以搜索 python 为例说明,用 chrome 的开发者者工具可以查看到请求的 URL 以及 response 的数据。
这是搜索时用到的 URL:http://www.jianshu.com/search/do?q=python&page=1&type=notes,q=python 表示搜索的关键字是 python,page 表示的是页数,但是在爬取时只能爬取前 100 页,每页 10 条数据,后面的文章请求不到,在浏览器中也无法查看。
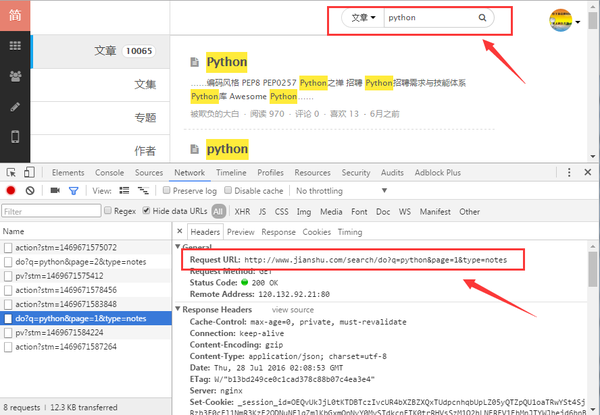
搜索文章
下面的是 response 的数据,也正是我们要抓取的内容。
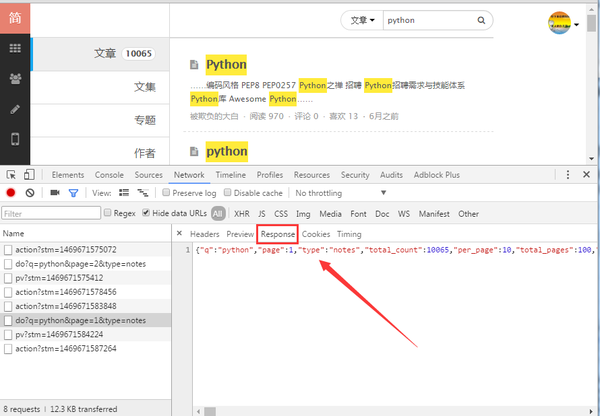
响应的数据
请求到每页的数据如下所示:
{\"q\":\"python\",\"page\":1,\"type\":\"notes\",\"total_count\":9993,\"per_page\":10,\"total_pages\":100,\"entries\":
[{\"id\":2851052,\"title\":\"Python\",
\"slug\":\"e1a9af9b48a4\",\"content\":\"……编码风格 \\n PEP8 PEP0257
Python之禅 \\n 招聘 \\n
Python招聘需求与技能体系 \\n
Python库 \\n Awesome Python……\",
\"user\":{\"id\":857942,\"nickname\":\"被欺负的大白\",\"slug\":\"175b9cfd71fb\"},
\"notebook\":{\"id\":3010085,\"name\":\"资源收集\"},\"public_comments_count\":0,\"likes_count\":13,\"views_count\":960,\"total_rewards_count\":0,
\"first_shared_at\":\"2016-01-17T12:16:54.000Z\"},返回的数据是字符串类型的 JSON 数据,先将其强制转换为 dict,然后从 entries 属性中获取文章的详细信息。代码请查看 GitHub 项目下 update_search_jianshu.py 文件。
代码中存在的问题:简书设置未登录用户 10 秒中只能搜索一次,目前还没有加入绕过登录的功能,可以在请求时加入
cookie文件绕过登录,或者向其登录表单提交账号认证。
5. 生成 API
将上面爬取到的文章保存到 MySQL 中,使用 Django REST framework 来生成 API,若对此功能不熟悉的请查 Django REST framework 官方文档 。
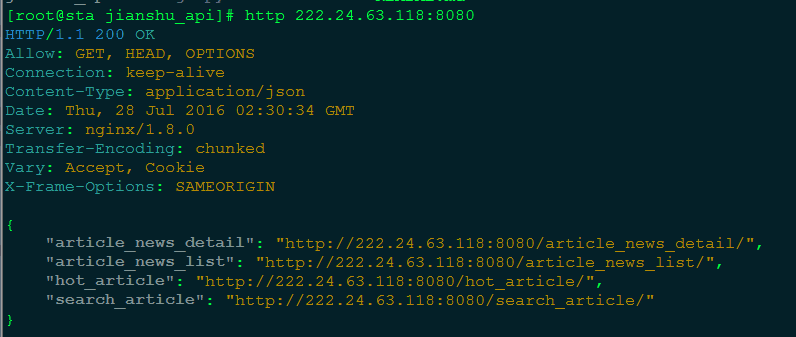
简书 API
6. 部署上线
- 使用 nginx + uwsgi + django + supervisor 进行环境部署
或者 - 使用 docker 进行环境部署