Python 爬取落网音乐
更新
很意外,这只爬虫和技术文章很早就写了。最近想在简书推广一下自己小玩意,搞点 star.
没想到,其他的没什么人关注。这篇完全从我博客复制过来的却活了。
为了不让大家,白白关注,大周末的我起早又来完善一下文档和程序啦。
谢谢大家关注。
源码:https://github.com/wuchangfeng/Crawler/tree/master/LuoWang
关于
爬取落网音乐下载至本地,随便你听。
落网的音乐逼格真的很高,都是自己喜欢的民谣类型,故爬虫抓取之。强烈推荐大家去欣赏落网的音乐,如果有兴趣也可以知乎一下落网的历史。真的非常不错。
另外,这个爬虫也只做学习之用,如若有其他不合适之处,请告知。
说明
整个网站还是很简单的,没有模拟登陆,验证码啥的,甚至请求头都不用写。爬虫也没有写的太暴力,\”温柔\”的爬取,为此加了延时,另一方面也是怕被识别出是机器。
不过我早上测试了一下程序,下载确实很慢。我暂时也还没想出一些优化的办法。
如果有人有兴趣或者想法,可以去 GitHub fork 一下,一起完善。目前已经有人像我 提交代码啦,非常开心。
最新版的支持 Linux 和 Windows。
准备
- 工具:python 2.7,PyCharm
- 类库:Requests,BeautifulSoup4,os
注意对于 BeautifulSoup4 在 CMD 下:pip install BeautifulSoup4。不要忘了后面的 4。当然你也要安装 pip 这个工具。
分析
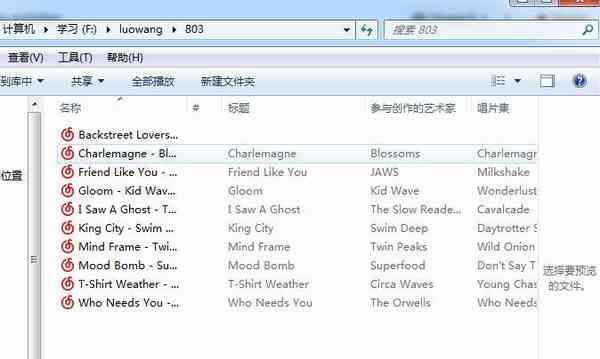
- 进入落网官网,发现如下图所示,其中801(可以自己输入相应期刊)就是期刊,每一期都有十左右首音乐。
luowang1.png
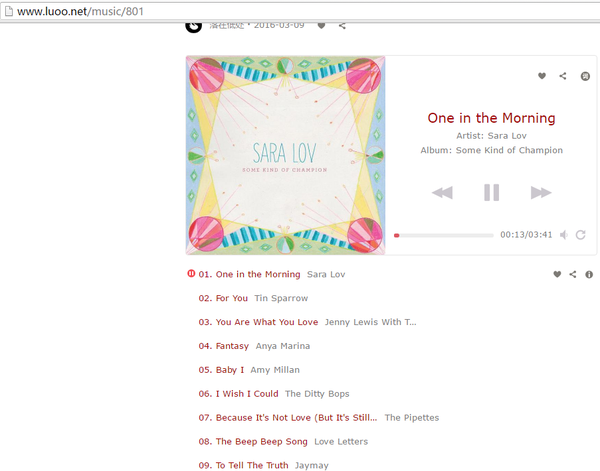
- 点击页面进入HTML元素页面,可以看见歌曲名字,专辑名,歌者,但是怎么没有歌曲资源的url?

- 没有歌曲的url我们就不能下载,那么我们要看看我们每一次换歌曲,发生了什么请求,点击审查元素,如下结果。

luowang2.png
- 如上图所示一个Request url,我们复制进浏览器地址输入栏,发现如下所示,没错这就是我们下载的 url 了。
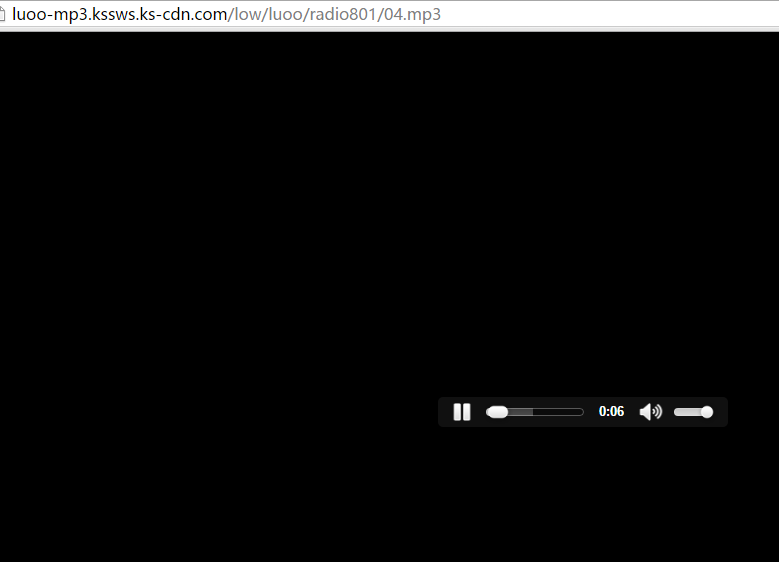
luowang3.png
开始
-
开始之前我们要获取歌曲相应的信息,我们采用 bs 这个库来解析HTML元素。
-
我们采用 Requests 来进行网络请求与下载,下载音乐就要用到稍微逼格高一点的用法了,我们下载它的响应流文件。具体用法见Requests响应体内容工作流
核心
def download_songs(volumn):
songs = get_song_list(volumn)
#创建存储目录
filename = os.path.join(basePath,str(volumn))
if not os.path.exists(filename):
os.makedirs(filename)
# 转移到当前工作目录
os.chdir(filename)
print u\"开始下载\"
index = 0
for song in songs:
index += 1
track = \'%02d\' % index
# http://luoo-mp3.kssws.ks- cdn.com/low/luoo/radio801/01.mp3 # volumn就是801页面,01就是歌曲标识
r = requests.get(MP3_URL.format(volumn,track), stream=True)
song_name = SONG_NAME.format(song[\'name\'], song[\'artist\'])
# Requests 获取头部响应流
with open(song_name, \'wb\') as fd:
for chunk in r.iter_content():
fd.write(chunk)
fd.close()
print u\"{}下载成功\".format(song[\'name\'])
# 延时
time.sleep(1);
print u\"开始下载下一首,干点别的去吧\"如上即是整个代码的核心下载模块,即 Requests 部分。
总结
- 抓取还是比较简单的,只用到了基本的 Requests 和 Beautifulsoup4,只是很难想到要流式读取响应头,这是 Requests 的高级用法。
- 我们抓取的目的就是把歌曲下载到本地,自由不用联网的听,速度个人感觉不要太追求,不要给人家服务器造成压力。
结果
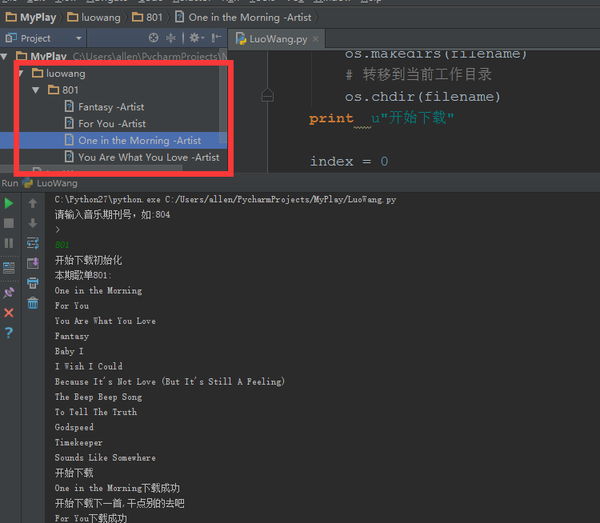
luowang5.png