
Scrapy爬取图片
有半个月没有更新了,最近确实有点忙。先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章。为了表达我的歉意,我给大家来一波福利。。。

今天咱们说的是爬虫框架。之前我使用python爬取慕课网的视频,是根据爬虫的机制,自己手工定制的,感觉没有那么高大上,所以我最近玩了玩 python中强大的爬虫框架Scrapy。
Scrapy是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便。Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
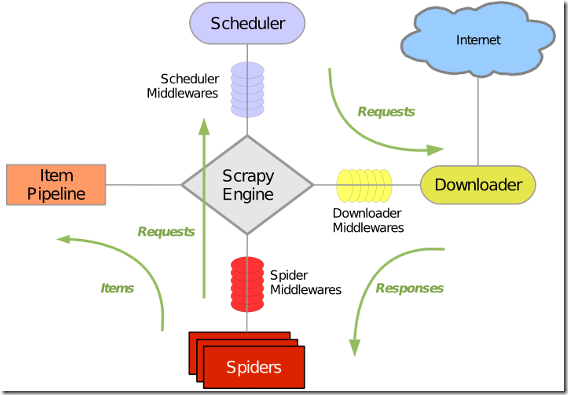
绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
简要介绍了Scrapy的工作流程,咱们开始直奔主题,使用Scrapy爬取美女图片。
大家注意今天不是讲Scrapy基础教程,咱们在之后的七夜音乐台开发的时候会讲解。所以咱们今天直接上手。
以煎蛋网(http://jandan.net)为例子:

咱们来到煎蛋网首页,其中有一个栏目是妹子,今天的目标就是它。
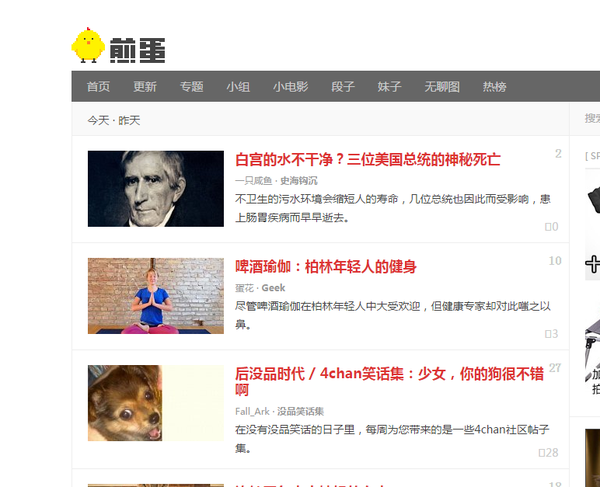
图片的分类是按页进行排列,咱们要爬取所有的图片需要模拟翻页。
打开火狐中的firebug,审查元素。
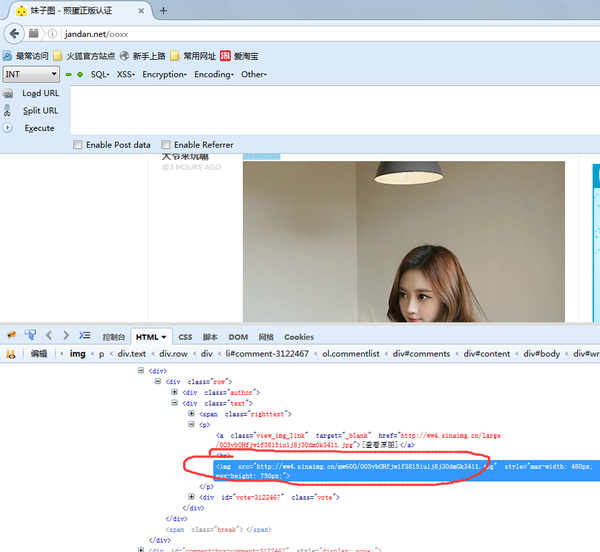
这是咱们需要的图片链接,只要获取这个链接,进行下载就可以了。
咱们看看翻页后的链接是什么???
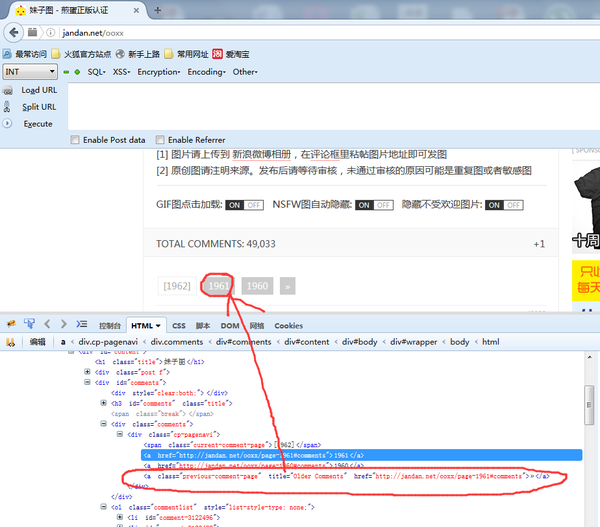
咱们只要解析出红线圈出的这个标签,就可以知道下一页的链接了,就是这么简单。好了,这时候就可以写代码了。。。
打开cmd,输入scrapy startproject jiandan,这时候会生成一个工程,然后我把整个工程复制到pycharm中(还是使用IDE开发快)。
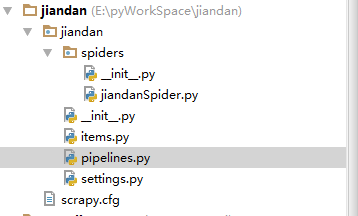
上图就是工程的结构。
jiandanSpider.py ——Spider 蜘蛛
items.py —————–对要爬取数据的模型定义
pipelines.py————-咱们最终要存储的数据
settings.py—————-对Scrapy的配置
接下来我把代码贴一下:
jiandanSpider.py:
#coding:utf-8
import scrapy
from jiandan.items import JiandanItem
fromscrapy.crawler import CrawlerProcess
class jiandanSpider(scrapy.Spider):
name =\’jiandan\’
allowed_domains = []
start_urls = [\”http://jandan.net/ooxx\”]
defparse(self, response):
item = JiandanItem()
item[\’image_urls\’] = response.xpath(\’//img//@src\’).extract()#提取图片链接
# print \’image_urls\’,item[\’image_urls\’]
yield item
new_url= response.xpath(\’//a[@class=\”previous-comment-page\”]//@href\’).extract_first()#翻页
# print \’new_url\’,new_url
if new_url:
yield scrapy.Request(new_url,callback=self.parse)
items.py :
# -*- coding: utf-8 -*-
import scrapy
class JiandanItem(scrapy.Item):
# define the fields for your item here like:
image_urls=scrapy.Field()#图片的链接
pipelines.py:
# -*- coding: utf-8 -*-
importos
importurllib
from jiandan import settings
class JiandanPipeline(object):
def process_item(self, item, spider):
dir_path=\’%s/%s\’%(settings.IMAGES_STORE,spider.name)#存储路径
print\’dir_path\’,dir_path
if not os.path.exists(dir_path):
os.makedirs(dir_path)
for image_url in item[\’image_urls\’]:
list_name=image_url.split(\’/\’)
file_name=list_name[len(list_name)-1]#图片名称
# print \’filename\’,file_name
file_path=\’%s/%s\’%(dir_path,file_name)
# print \’file_path\’,file_path
if os.path.exists(file_name):
continue
with open(file_path,\’wb\’) as file_writer:
conn=urllib.urlopen(image_url)#下载图片
file_writer.write(conn.read())
file_writer.close()
return item
settings.py:
# -*- coding: utf-8 -*-
# Scrapy settings for jiandan project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
#http://doc.scrapy.org/en/latest/topics/settings.html
#http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME=\’jiandan\’
SPIDER_MODULES=[\’jiandan.spiders\’]
NEWSPIDER_MODULE=\’jiandan.spiders\’
ITEM_PIPELINES={
\’jiandan.pipelines.JiandanPipeline\’:1,
}
IMAGES_STORE=\’E:\’
DOWNLOAD_DELAY=0.25
最后咱们开始运行程序,cmd切换到工程目录,
输入scrapy crawl jiandan,启动爬虫。。。
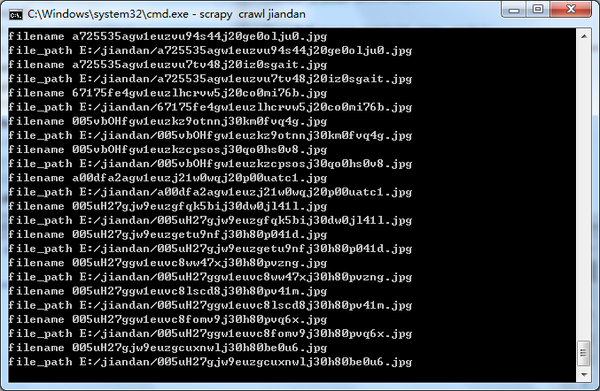
大约20分钟左右,爬虫工作结束。。。
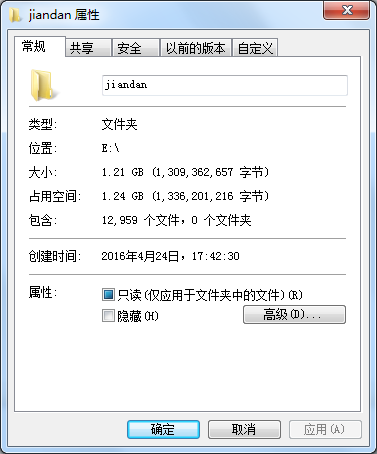
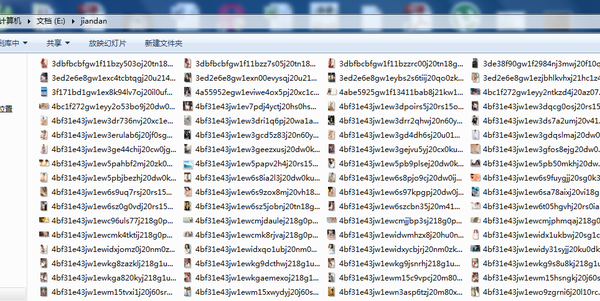
咱们去看看美女图吧,居然有1.21G。。。
今天的分享就到这里,如果大家觉得还可以呀,记得打赏呦。

感谢大家的关注,加我的微信,咱们进行交流。